Kubernetes 是一個容器編排系統。當一個後端包含許多不同的服務,必須在節點間持續運作、具備跨通訊能力和可擴充性時,一個編排系統便至關重要。隨著容器日益普及,使用 Kubernetes 進行編排也變得越來越受歡迎。
搭配容器和 Kubernetes,我們擁有多種共通的佈署、發現、擴充和監控方法,遍及系統內的所有語言和執行時期。在本章中,我們將探討 Kubernetes 的核心組成,以及如何使用這些組成來佈署和管理我們在先前的章節中建置的 service_discovery 服務。
執行 Kubernetes
為了開發和測試 Kubernetes 佈署,我們需要在當地執行 Kubernetes 以供測試。下列章節是以 microk8s 作為本地的 Kubernetes 測試,但應適用於任何用於執行 Kubernetes 的本地或雲端選項。若需要針對本地測試提供特定指示時,將使用 microk8s。持續整合和佈署到生產環境的指示則會使用 Google Kubernetes Engine。不過,大部分的內容都應能輕鬆適用於以下兩個章節中的任何服務。
本地
- microk8s:Ubuntu 背後的公司 Canonical 所提供的服務,但會在許多 Linux 散佈版、Windows 和 MacOS 上執行。microk8s 安裝容易,而且可以快速上手。它會在本地執行,而非像 minikube 那樣在 VM 中執行,因此比較不會佔用資源。
- minikube:最舊且最靈活的選項,現在也是 Kubernetes 專案的正式參與者之一。
minikube支援不同管理程式,而且有選擇不建立新虛擬機的選項,但它仍然建議在 Linux VM 中執行。 - k3s 和 k3d:k3s 是 Rancher Labs 推出的輕量級 Kubernetes。k3s 移除了傳統和非預設的功能以縮小體積,並以 SQLite3 取代 etcd,這讓 k3s 成為 CI 和本地測試的優良選擇。k3d 則是用於在 Docker 中執行 k3s 的輔助工具。
- kind:Kubernetes in Docker 是由 Kubernetes SIG 所支援的專案,用於在 Docker 中執行 Kubernetes,最初用於測試 Kubernetes 本身。
- Docker for Mac Kubernetes:在 MacOS 上執行時,是最容易上手的。
生產
所有大型雲端供應商都提供受管理的 Kubernetes 群集
- Google Kubernetes Engine:在沒有使用 microk8s 的情況下,本章節使用 Google Cloud,這是因為它提供 $300 的額度,適用於新使用者註冊
- Digital Ocean Kubernetes
- AWS Elastic Container Service for Kubernetes
- Azure Kubernetes Service
還有 更多選擇 可以部署至雲端或私人伺服器。選擇解決方案時會有許多考量因素,例如在現有公司中,您目前的服務託管在哪裡。幸運的是,Kubernetes 讓您可以彈性選擇供應商來進行部署。
部署
在 Kubernetes 中,容器是 Pod 的一部分。每個 Pod 有 1 個以上的容器,以及 0 個或更多個 init-containers,後者會在其他容器啟動前執行一次。針對應用程式,會使用稱為 Deployment 的抽象層級,因此不用手動建立個別 Pod 來進行部署或擴充。Deployment 是一種宣告式的方式,可用來建立及更新應用程式的 Pod。
每個 Kubernetes 資源都在 yaml 檔案中定義,其中包含 apiVersion、資源的 kind、metadata(例如名稱),以及資源規格。
apiVersion: apps/v1
kind: Deployment
metadata:
name: service-discovery
spec:
[...]
我們在此討論的 Deployment 規格項目為 selector、replicas 和 template。selector 是 Pod 屬於 Deployment 的規格。matchLabels 表示具有標籤 app 值為 service-discovery 的 Pod,在同一個 Namespace 中,視為 Deployment 的一部分。replicas 宣告 Pod 的執行個數。
spec:
selector:
matchLabels:
app: service-discovery
replicas: 1
template:
[...]
template 區段是 Pod 範本,並定義 Deployment 所執行的 Pod 規格。
template:
metadata:
labels:
app: service-discovery
spec:
shareProcessNamespace: true
containers:
- name: service-discovery
image: service_discovery
ports:
- containerPort: 8053
protocol: UDP
name: dns
- containerPort: 3000
protocol: TCP
name: http
- containerPort: 8081
protocol: TCP
name: grpc
首先,Pod metadata 設定與 Deployment 規格中的 selector 匹配的標籤 – 在接下來的區段 使用 Kustomize 簡化部署 中,我們會看到免除重複定義 labels 的方法。然後,Pod 規格有容器清單。在這個情況中,有一個容器可以透過 DNS、HTTP 和 GRPC 存取埠。
僵屍殺手!
在 Docker 章節 中所討論的僵屍程序問題(已退出但其 PID 卻仍然存在的程序,因為父程序尚未呼叫 wait()),也適用於使用 Kubernetes 執行容器。要防止它們產生的一種方法(也就是 `service_discovery` 專案所使用的方法)是在 Pod 中的容器間使用共用的程序命名空間。
這在 Pod 規格中使用 `shareProcessNamespace: true` 來完成。此設定表示在容器中啟動的程序不會是 PID 1。反之,PID 1 是 Kubernetes 暫停容器。暫停容器在 Pod 中永遠是父容器,但搭配此設定(會讓所有程序的 PID 1 在 Pod 中都相同),它就能回收 Pod 中任何容器可能會產生的僵屍程序。
在此處閱讀更多有關 Kubernetes 文件中的共用程序命名空間 的資訊。
容器資源
Pod 規格中的每個容器規格都可包含記憶體和 CPU 的資源需求和限制。需求是用來排程 Pod。排程包括選擇一個節點,讓所需求的 CPU 和記憶體可用(節點上的其他 Pod 尚未需求)。
resources:
requests:
memory: "250Mi"
cpu: "500m"
limits:
memory: "1Gi"
cpu: "2000m"
此外,CPU 需求會轉換為 cgroup 屬性 cpu.shares。每個 CPU 都被視為 1024 個時間片,而且 CPU 需求會告訴核心要嘗試給程序多少個時間片。但是,如果只設定時間片,對於一個程序最終能實際取用多少資源沒有上限。我們需要 Kubernetes 資源限制來限制使用過多 CPU 時間的程序。
限制會轉換為 Linux 核心排程器要對程序執行的 CPU 頻寬控制。頻寬控制有一個週期(是某個微秒數)和一個配額(程序在一個週期內能使用的最大微秒數)。這個週期永遠都是 100000 微秒,所以以上述範例為例,如果 CPU 限制設定為 2000m 的話,設定的 cgroup 配額將是 200_000,表示每 100_000 微秒能使用 2 個 CPU。
如果在一個週期內超過限制,核心就會限制程序,不在下一個週期之前允許它再次執行。這便是為什麼正確設定 Erlang VM 排程器數量以及限制 VM 執行忙碌等待的時間非常重要的原因。
忙碌等待是一種僵化的迴圈,Erlang 排程器會在迴圈中等待更多工作執行,最終會進入休眠狀態。這個僵化的迴圈會消耗 CPU,只為等待實際的工作,且可能導致更差的效能,因為 Erlang 程式碼很可能因核心排程器而受到節流限制。接著當有實際工作需要完成時,Erlang 虛擬機器可能會處於完全沒有 CPU 時段的期間。如果虛擬機器執行的排程器數量多於配置的 CPU 數目,情況會更糟。CPU 限制為 2000m,我們認為表示 2 個 CPU 核心,但事實上並不會將程序限制在 2 個核心。如果正在使用 8 個排程器,且節點上具有相同數量的核心,8 個排程器仍然會散布在所有核心上,並平行執行。但配額仍為 200000,當 8 個排程器在 8 個核心上花費時間時,更有可能會超出限制。即使沒有忙碌等待,排程器也必須自行進行工作,而且可能會在嘗試保持某些 CPU 使用限制時造成不必要的開銷。
為了停用排程器忙碌等待,我們在 vm.args.src 中設定虛擬機器引數 +sbwt,如下所示
+sbwt ${SBWT}
自 OTP-23 起
自 2020 年發布的 OTP-23 起,Erlang 虛擬機器具備「容器感知」能力,且將根據容器配置的資源自動設定適當數量的活動排程器。在 OTP-23 之前,需要使用 +S 引數來將活動排程器數量設定為等於容器的 CPU 限制。
此外,自 OTP-23 起,+sbwt 預設設為 very_short。這是一項改善,但您可能仍希望在 Kubernetes 或類似環境中執行時,將值設定為 none。不過,一如往常,請務必執行效能評量,以找到最適合您特定工作負載的最佳值。
容器環境及 ConfigMap
正如我們在「版本」章節中所見,執行時間組態是透過在 vm.args.src 及 sys.config.src 中進行環境變數替換來完成的。因此,我們必須將這些變數插入容器的環境中。Kubernetes Pod 中的每個容器都可以有一個 env 欄位,用於宣告一組環境變數。最簡單的情況是明確提供一個 name 和一個 value
env:
- name: LOGGER_LEVEL
value: error
- name: SBWT
value: none
這個組態會在環境變數 LOGGER_LEVEL 中產生值 error。
存在其他環境變數,必須根據正在執行的容器的狀態進行設定。其中一個範例是根據 Pod 的 IP 設定 NODE_IP 變數
env:
- name: NODE_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
fieldRef 下的 status.podIP 宣告將在建立 Pod 時回傳目前的 Pod IP。
使用者定義的環境變數,例如 LOGGER_LEVEL,可以專門針對稱為 ConfigMap 的組態 Kubernetes 資源進行更好的追蹤。 ConfigMap 包含鍵值對,並可根據檔案、檔案目錄或文字值進行填入資料。在這裡,我們將使用文字值將 LOGGER_LEVEL 設定為 error
apiVersion: v1
kind: ConfigMap
metadata:
name: configmap
data:
LOGGER_LEVEL: error
然後,在 Deployment 資源中, LOGGER_LEVEL 值可以設定為 ConfigMap 的參照
env:
- name: LOGGER_LEVEL
valueFrom:
configMapKeyRef:
name: configmap
key: LOGGER_LEVEL
使用 envFrom 可以在使用 ConfigMap 定義的所有變數納入做為容器的環境變數的快捷方式
envFrom:
- configMapRef:
name: configmap
現在,定義在 ConfigMap 中的所有變數都會新增至容器,而不必個別指定每一個變數。有關定義 ConfigMap 的詳細資訊,請參閱後續部分 使用 Kustomize 簡化部署。
提示
更新 ConfigMap 中的值不會觸發參照 ConfigMap 的 Deployments 來使用新的環境變數重新啟動其容器。反之,當組態變更時,更新容器的方式是建立一個具有必要變更和新名稱的新 ConfigMap,然後修改由 Deployment 在 configMapRef 下參照的 ConfigMap 的名稱。舊 ConfigMap 最終會被 Kubernetes 清除,因為它們未在任何地方被參照,而且 Deployment 會使用新組態重新建立其 Pods。
初始化容器
我們的 service_discovery 版本依賴 Postgres 資料庫來儲存狀態,為確保在執行容器之前資料庫正確設定,我們會使用 初始化容器。每個 初始化容器 都是一個容器,必須在 Pod 中任何主要容器執行之前執行完畢。用於執行遷移作業的資料庫遷移工具 flyway 用於驗證資料庫為最新狀態,才能允許主要容器執行
volumes:
- name: migrations
emptyDir:
medium: Memory
initContainers:
- name: flyway
image: flyway/flyway:9.22
name: flyway-validate
args:
- "-url=jdbc:postgresql://$(POSTGRES_SERVICE):5432/$(POSTGRES_DB)"
- "-user=$(POSTGRES_USER)"
- "-password=$(POSTGRES_PASSWORD)"
- "-connectRetries=60"
- "-skipCheckForUpdate"
- validate
volumeMounts:
- name: migrations
mountPath: /flyway/sql
env:
- name: POSTGRES_SERVICE
value: POSTGRES_SERVICE
- name: POSTGRES_DB
value: POSTGRES_DB
- name: POSTGRES_USER
value: POSTGRES_USER
- name: POSTGRES_PASSWORD
value: POSTGRES_PASSWORD
- name: service-discovery-sql
image: service_discovery
command: ["/bin/sh"]
args: ["-c", "cp /opt/service_discovery/sql/* /flyway/sql"]
volumeMounts:
- name: migrations
mountPath: /flyway/sql
Migrations 磁碟僅存在於記憶體中,用於將目前的 SQL 遷移檔案從版本映像檔複製到共享目錄, flyway 容器會使用該目錄來執行驗證。會使用具備 medium memory 的 emptyDir 類型的磁碟,因為我們不會使用這個磁碟來儲存任何資料,只會用於兩個 初始化容器 之間共用。如果未包含 medium: Memory,則 emptyDir 會在主機檔案系統建立,但對每個新的 Pod 仍會是空的,並會在 Pod 刪除時移除。
準備、健全和啟動探詢
Pod 中的每個容器都可以定義 Readiness、Liveness 和 Startup 探詢。探詢定義為在容器中執行的命令、對給定連接埠和路徑執行的 HTTP GET 要求,或嘗試對特定連接埠開啟 TCP 連線。
雖然 Kubernetes 會重新啟動任何失敗的容器,但有時程序會變得沒有反應,例如死結。livenessProbe 可用於此類情況,其中停止回應會提示重新啟動。因此,如果包含 livenessProbe,應盡量簡單。通常更安全的做法是完全略過 livenessProbe,並依賴於節點崩潰、基於指標的警報和自動擴展。
自動擴展的一部分基於 readinessProbe。readinessProbe 告訴 Kubernetes Pod 已準備好接收流量。當 Pod 因容器使 readinessProbe 失敗而變為 unready,它會從 Service 中移除,導致流量導向剩餘的 Pod,增加它們的負載,然後啟動新的 Pod。
不使用 livenessProbe 作為此目的,表示容器仍可用,因為它們尚未中止,可以檢查檢查失敗的原因。這表示附加一個殼層(如果它沒有完全凍結)或強制寫入崩潰傾印。在資源非常受限的環境中,您可能比較希望 livenessProbe 為了讓陷入死結的容器及其 Pod 立即清理,而不是等待手動介入,讓自動擴展器在負載下降後縮小規模。
readinessProbe 的另一用途是,如果應用程式必須定期執行您不希望處理請求的工作,或必須進行某種維護,它可以傳回 503 狀態回應,表示準備從 Service 後端移除。
在 Pod 組態中不需要任何特殊項目來執行優雅關閉,無論是在部署、livenessProbe 失敗或縮小規模期間。當 Kubernetes 傳送 SIGTERM 來表示關閉時,Erlang 將呼叫 init:stop()。如 版本 中所述,每個應用程式將按照相反的順序停止,每個應用程式的督導樹將以相反的順序終止子級。
在預設情況下,程序可以等待長達 30 秒(可使用 terminationGracePeriodSeconds PodSpec 選項進行設定),然後 Kubernetes 傳送 SIGKILL 訊號,這將強制程序終止。
部署和 readinessProbe 的一個重要注意事項是如果 readinessProbe 從未通過時的行為。在部署過程中,如果 Pod 從未通過其 readinessProbe,則視部署策略而定,Pod 從 Ready 的部署先前版本可能仍會持續到通過為止。這在以下部分 滾動部署 中有更詳細的說明。
在 service_discovery 項目中,只定義 readinessProbe 以便將 Pod 從 Service 後端移除,而不中止容器
readinessProbe:
httpGet:
path: /ready
port: http
initialDelaySeconds: 0
periodSeconds: 10
有了這個配置,我們希望初步的檢查至少會失敗一次,因為在 service_discovery_http 應用程式繫結到一個埠以偵聽 HTTP 請求之前的實際啟動時間長於 0 秒。這將導致 Probe 處理的 連線拒絕 錯誤
service-disc… │ [event: pod service-discovery-dev/service-discovery-dev-645659d699-plxfw] Readiness probe failed: Get "http://10.244.0.114:3000/ready": dial tcp 10.244.0.114:3000: connect: connection refused
儘管失敗,而且 periodSeconds 為 10,這個 Pod 大約不會花費 10 秒鐘才能準備就緒。在 initialDelaySeconds 為 0 的情況下,readinessProbe 會在啟動期間立即檢查,而不會等待配置的 periodSeconds 再檢查一次。因為該服務在啟動時只有少許動作,所以會通過第二次檢查。如果沒有通過,這個 Pod 將會等待 periodSeconds,直到再次檢查,並準備就緒。
為了盡可能簡單,readinessProbe 被定義於 service_discovery_http 中,如下所示:
handle('GET', [<<"ready">>], _Req) ->
{ok, [], <<>>};
這表示它與對 /ready 的 GET 請求相符,並立即傳回一個 200 回應。除了這個服務能夠接收和回應 HTTP 請求之外,沒有任何有關服務功能的額外檢查。
滾動式佈署
Kubernetes Deployment 資源有一個可配置 策略,以決定在佈署新版本的映像時會發生什麼。service_discovery Deployment 使用滾動式更新策略。另一種策略是 Recreate,這表示 Kubernetes 會先終止 Deployment 中的所有 Pods,然後啟動新的 Pods。對於 RollingUpdate 策略,Kubernetes Deployment 控制器會啟動新的 Pods,然後終止舊 Pods。有兩個配置變數可以告訴控制器,允許多少個 Pods 超過所需的數量 (maxSurge),以及允許多少個 Pods 在佈署期間不可用 (maxUnavailable)。
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 0
maxSurge: 25%
service_discovery 已配置 maxUnavailable 為 0,且 maxSurge 為 25%。這表示,如果已擴充至四個副本,則在佈署期間將會啟動一個新的 Pod,當該 Pod 的 readinessProbe 通過時,一個舊的 Pod 將開始終止,且新的 Pod 將會啟動。這個程序將會持續執行四次。
服務
Service 是一個資源,用於定義如何於網路上公開應用程式。每個 Pod 都擁有自己的 IP 位址,且可以公開埠。Service 提供一個 IP 位址 (Service 的 ClusterIP),且可以將該 IP 上的埠對應至應用程式中每個 Pod 的公開埠。在以下的資源定義中,建立一個名為 service-discovery 的 Service,並使用選擇器 app: service-discovery,以對應在先前區段建立的 Pods
kind: Service
apiVersion: v1
metadata:
name: service-discovery
spec:
selector:
app: service-discovery
ports:
- name: dns
protocol: UDP
port: 8053
targetPort: dns
- name: http
protocol: TCP
port: 3000
targetPort: http
- name: grpc
protocol: TCP
port: 8081
targetPort: grpc
部署 的容器公開了三個埠,且給予每個埠一個名稱,分別為 dns、http 和 grpc。服務 使用這些名稱作為其公開的每個埠的 targetPort。在此資源套用到 Kubernetes 集群後,將會有一個在三個埠上偵聽的 IP,並會代理到其中一個正在執行的 莢艙。
使用代理程式 (kube-proxy) 來將流量路由到 莢艙,而不是將每個 莢艙 的 IP 加入 DNS 記錄,是因為 服務 實際執行的 莢艙 變動率很高的緣故。倘若使用 DNS,就需要低延遲或沒有延遲存活時間 (TTL) 並且仰賴客戶端完全遵守 TTL 值。讓每個請求都透過代理程式路由意味著,只要代理程式的資料已被更新,就能將請求路由到正確的 莢艙 組合。
會監控新 服務並針對每個服務建立 DNS 記錄 [service-name].[namespace] 的 Kubernetes 感知 DNS 服務例如 CoreDNS。在使用命名埠的情況下(如 service-discovery 服務 的三個埠),還會建立格式為 _[name]._[protocol].[service-name].[namespace] 的 SRV 記錄。向 DNS 服務查詢 SRV 記錄(例如 _http._tcp.service-discovery.default)將會傳回 服務 DNS 名稱 service-discovery.default 和埠 3000。
在群集的後續小節中,我們將看到如何使用 無頭服務 (ClusterIP 設為 None 的 服務) 資源和命名埠,透過沒有 Erlang 埠映射守護程式 (epmd) 的分散式 Erlang 連接 Erlang 節點。
使用 Kustomize 簡化部署
現在我們已經討論了用於我們應用程式的兩個主要 Kubernetes 資源,可以深入探討如何實際撰寫和部署這些資源。在各個資源的前幾小節中顯示的 YAML 檔案並未用於部署,原因在於它是靜態的,有時會重複(例如需要在 部署 中定義同一組標籤兩次),並且需要手動修改資源,或擁有部署到需要不同設定的不同環境的資源複製品。我們需要一個易於了解且能輕易執行變更的功能,例如更新容器中使用的影像、根據環境對資源使用不同的名稱或命名空間,或根據環境對 ConfigMap 使用不同的值。
有幾個開放原始碼選項可以和 Kubernetes 資源搭配使用。最受歡迎的兩個選項是 Helm 和 Kustomize。這兩個都是 Kubernetes 專案的一部分,但對於問題有截然不同的解決方案。Helm 使用 Go 範本 來撰寫和呈現 YAML。有些人(包括作者在內)發現對 YAML 進行範本化太過複雜、容易出錯且極為惱人。很幸運的是,另一項解決方案 Kustomize 不依賴範本。
Helm 3
即使 Helm 不用於專案的部署,仍可對相依關係的部署有所助益。有許多 Helm Charts 可運用,假若專案並非僅供內部使用,你可能會想要將其透過這類圖表提供給外界。
Helm 有許多問題,除了範本的部分,我們在這裡不會深入探討,但可說明這些問題會在最新的主要版本 Helm v3 中解決,且其已於 2019 年 11 月首次推出穩定版本。因此,我建議你進一步了解 Helm 的最新功能說明。
Kustomize 是 kubectl 的內建工具 (從 v1.14.0 開始),提供無範本的方式自訂 Kubernetes YAML 資源。我們將使用它產生不同環境的不同配置,以開發環境 dev 為開端,之後會在下一個章節 針對在地端開發安裝 Tilt 中使用,以便在地端執行 service_discovery。
設定是以基本配置搭配不同環境的覆寫。覆寫可以增加資源,並修改基本圖層的資源。基本配置和兩個覆寫的目錄配置如下:
$ tree deployment
deployment
├── base
│ ├── default.env
│ ├── deployment.yaml
│ ├── init_validation.yaml
│ ├── kustomization.yaml
│ ├── namespace.yaml
│ └── service.yaml
├── overlays
│ ├── dev
│ │ ├── dev.env
│ │ └── kustomization.yaml
│ └── stage
│ ├── kustomization.yaml
│ └── stage.env
└── postgres
├── flyway-job.yaml
├── kustomization.yaml
├── pgdata-persistentvolumeclaim.yaml
├── postgres-deployment.yaml
└── postgres-service.yaml
kustomization.yaml 的基本項包括 service_discovery 專案的主要資源,亦即 Namespace、Deployment 和 Service
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: service-discovery
commonLabels:
app: service-discovery
resources:
- namespace.yaml
- deployment.yaml
- service.yaml
commonLabels 下的標籤會加入每個資源,且因為可以移除 labels 項目和 selector,因此可簡化上一個章節的 Deployment 配置。因此,現在位於 deployment/base/deployment.yaml 中的 service_discovery 的 Deployment 資源看起來像這樣
apiVersion: apps/v1
kind: Deployment
metadata:
name: service-discovery
spec:
replicas: 1
template:
spec:
containers:
- name: service-discovery
image: service_discovery
[...]
當呈現資源時,Kustomize 會在 metadata 下插入標籤,也會在 spec 的 selector 欄位 matchLabels 下自動插入相同的標籤。如欲了解 Kustomize 會產生什麼檔案,可以在基礎項目上執行 kubectl kustomize,然後,它會將資源列印到標準輸出
$ kubectl kustomize deployment/base
[...]
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: service-discovery
name: service-discovery
namespace: service-discovery
spec:
replicas: 1
selector:
matchLabels:
app: service-discovery
template:
metadata:
labels:
app: service-discovery
[...]
改善 Deployments 建立的另一個功能是產生 ConfigMaps。在上一個關於環境變數和 ConfigMaps 的章節中,我們以 Deployment 結尾,其中包含來自 ConfigMap 資料的環境變數
envFrom:
- configMapRef:
name: configmap
透過 Kustomize 的 configMapGenerator,我們可以宣告 ConfigMap 會根據具備 VarName=VarValue 之行的任何檔案而產生
configMapGenerator:
- name: configmap
envs:
- dev.env
dev.env 的內容如下:
LOGGER_LEVEL=debug
kubectl kustomize deployment/overlays/dev 的輸出結果所看到的 ConfigMap 為:
apiVersion: v1
data:
LOGGER_LEVEL: debug
kind: ConfigMap
metadata:
labels:
overlay: dev
name: configmap-dev-2hfc445577
namespace: service-discovery-dev
請注意名稱不再僅為 configmap,而是 configmap-dev-2hfc445577。如果內容變更,Kustomize 將建立新的 ConfigMap、其名稱有所不同,而且將更新對 ConfigMap 的任何參照。更新 Deployment 規範中對 ConfigMap 的參照可確保在配置變更時重新啟動 Pod。否則,單純修改 ConfigMap 不會導致更新執行中的 Pod。因此在 Kustomize 輸出中,Deployment 將擁有
- envFrom:
- configMapRef:
name: configmap-dev-2hfc445577
對 Secret 也執行相同步驟。
若要分一個步驟套用 Kustomize 所產生的資源,可以將 -k 選項傳遞給 kubectl apply
$ kubectl apply -k deployment/overlays/dev
此命令將根據 dev 疊加層產生資源,並將它們套用至 Kubernetes 群集。
資料庫遷移
作業
一個 Kubernetes Job 會建立一個或多個 Pod,並執行它們直到指定的數量成功完成。對於 service_discovery 的資料庫遷移,Job 是 1 個 Pod,其容器執行 Flyway,並與一個 initContainer 共用 Volume,該 initContainer 會從正在部署的 service_discovery 鏡像複製 SQL 檔案。成為 initContainers 表示在 Pod 的主要容器啟動前,它們必須全部執行完成並成功(狀態碼為 0)。因此,在 Job 的 Pod 的主要容器執行 flyway migrate 之前 (實際上與遷移一起的同一個鏡像使用的是我們用來執行 Deployment 的完整 service_discovery 發行版),它必須已成功將遷移複製到 /flyway/sql 目錄下的共用 Volume
apiVersion: batch/v1
kind: Job
metadata:
labels:
service: flyway
name: flyway
spec:
ttlSecondsAfterFinished: 0
template:
metadata:
labels:
service: flyway
spec:
restartPolicy: OnFailure
volumes:
- name: migrations
emptyDir:
medium: Memory
containers:
- args:
- "-url=jdbc:postgresql://$(POSTGRES_SERVICE):5432/$(POSTGRES_DB)"
- -user=$(POSTGRES_USER)
- -password=$(POSTGRES_PASSWORD)
- -connectRetries=60
- -skipCheckForUpdate
- migrate
image: flyway/flyway:9.22
name: flyway
volumeMounts:
- name: migrations
mountPath: /flyway/sql
env:
- name: POSTGRES_SERVICE
value: POSTGRES_SERVICE
- name: POSTGRES_DB
value: POSTGRES_DB
- name: POSTGRES_USER
value: POSTGRES_USER
- name: POSTGRES_PASSWORD
value: POSTGRES_PASSWORD
initContainers:
- name: service-discovery-sql
image: service_discovery
command: ["/bin/sh"]
args: ["-c", "cp /opt/service_discovery/sql/* /flyway/sql"]
volumeMounts:
- name: migrations
mountPath: /flyway/sql
使用 Job 執行遷移的問題在於,套用一組 Kubernetes YAML 資源時,無法更新已完成 Job 的鏡像,並導致重新執行。套用具有不同 service_discovery 鏡像且名稱相同的 Job 將產生錯誤。有幾個選項可以處理此限制。
一個選項,在 Kubernetes 1.16 中仍為 alpha 功能,就是設定 Job 規範中的 ttlSecondsAfterFinished: 0。使用此設定,Job 在完成後會立即符合刪除條件。然後,當下一個部署套用新的 Kubernetes 資源時,將建立新的 Job,而不是嘗試更新上一個部署的 Job。
ttlSecondsAfterFinished 選項仍然是 Alpha 功能,需要手動啟用。你可以在 Google Cloud 上透過建立一個 Alpha 群集 來試用這項功能,不過這些群集只能運作 30 天。另一種解法是手動(或使用在 CI 管線中執行的腳本)執行遷移,並在部署完成後刪除 作業。
在 kubectl apply 主程式以外執行 作業 的好處之一,就是如果 作業 失敗的話,就能停止部署。
驗證遷移
如果我們希望確保 service_discovery 容器在資料庫成功遷移後才會啟動,就可以使用 flyway 指令的 validate 命令。執行 flyway validate 的容器將會在它所偵測到的資料庫執行所有遷移後成功。結果的容器設定原則上與上一節中執行遷移時相同,但指令已從 migrate 改為 validate,而且 flyway 容器和將遷移複製到共用儲存區的容器都是 initContainers。
apiVersion: apps/v1
kind: Deployment
metadata:
name: service-discovery
spec:
replicas: 1
template:
spec:
volumes:
- name: migrations
emptyDir: {}
initContainers:
- name: service-discovery-sql
image: service_discovery
volumeMounts:
- name: migrations
mountPath: /flyway/sql
command: ["/bin/sh"]
args: ["-c", "cp /opt/service_discovery/sql/* /flyway/sql"]
- image: flyway/flyway:9.22
name: flyway-validate
args:
- "-url=jdbc:postgresql://$(POSTGRES_SERVICE):5432/$(POSTGRES_DB)"
- "-user=$(POSTGRES_USER)"
- "-password=$(POSTGRES_PASSWORD)"
- "-connectRetries=60"
- "-skipCheckForUpdate"
- validate
volumeMounts:
- name: migrations
mountPath: /flyway/sql
env:
- name: POSTGRES_SERVICE
value: POSTGRES_SERVICE
- name: POSTGRES_DB
value: POSTGRES_DB
- name: POSTGRES_USER
value: POSTGRES_USER
- name: POSTGRES_PASSWORD
value: POSTGRES_PASSWORD
在每個 init 容器執行完畢之前,下一個容器都不會啟動,因此這部份的順序非常重要。如果將遷移檔案複製到 /flyway/sql 的容器沒有出現在 initContainers 清單的第一個,而且 Kubernetes 要求在它成功完成執行才能啟動下一個容器,則在執行 flyway 之前就不會將遷移複製到儲存區。
Tilt for Local Development
Tilt 是一種用於在開發環境的本地端部署並更新 Docker 映像檔和 Kubernetes 部署的工具。預設情況下,它只會針對本地 Kubernetes(例如 microk8s、minikube 等)建置和部署服務,以防止意外將你的開發環境傳送至正式環境!
要開始使用 Tilt 最簡單的方法是使用本地 Kubernetes 群集中的儲存庫。對於 microk8s,可以很輕易地啟用儲存庫,我們此時也需要 DNS,因此也要同時啟用 DNS。
$ microk8s.enable registry
$ microk8s.enable dns
要允許主機 Docker 發佈至這個儲存庫,必須將它新增至 /etc/docker/daemon.json。
{
[...]
"insecure-registries" : ["localhost:32000"]
[...]
}
Tilt 透過專案根目錄中名為 Tiltfile 的檔案執行。逐步瀏覽 service_discovery 根目錄中的 Tiltfile,它會從下列開始
default_registry('127.0.0.1:32000')
default_registry 設定 Tilt 建置的 Docker 映像檔的推播位置,在此情況下,使用的是 microk8s 中啟用的儲存庫。實際上,不需要這行程式碼,因為 Tilt 會自行找出已啟用儲存庫的 microk8s 正在使用中,並自動設定自己以使用那個儲存庫。
接下來設定建置幾個 Docker 映像檔,從 service_discovery_sql 開始
custom_build(
'service_discovery_sql',
'docker buildx build -o type=docker --target dev_sql --tag $EXPECTED_REF .',
['apps/service_discovery_postgres/priv/migrations'],
entrypoint="cp /app/sql/* /flyway/sql"
)
此映像檔是根據 Dockerfile 目標 dev_sql 建置的
FROM busybox as dev_sql
COPY apps/service_discovery_postgres/priv/migrations/ /app/sql/
其中只包含 SQL 移轉檔並使用 busybox,以便 entrypoint 可以使用 cp。`custom_build` 的第三個引數 `['apps/service_discovery_postgres/priv/migrations']` 會指示 Tilt 在該目錄中的任何檔案發生變更時,重新建置映像,在此為 SQL 移轉檔。稍後在 Tiltfile 中進行 kustomize 部署時,我們會看到如何使用這個映像。
注意,這裡使用的是函式 custom_build。如果這符合你的需求,Tilt 會提供一個更簡單的函式 docker_build 來建置 Docker 映像。在 service_discovery 的案例中,我們在 Dockerfile 中有特定的 targets 要使用,並希望確保使用 buildx。
接下來要建置的映像是 service_discovery,這是 Deployment 使用的主要映像
custom_build(
'service_discovery',
'docker buildx build -o type=docker --target dev_release --tag $EXPECTED_REF .',
['.'],
live_update=[
sync('rebar.config', '/app/src/rebar.config'),
sync('apps', '/app/src/apps'),
run('rebar3 as tilt compile'),
run('/app/_build/tilt/rel/service_discovery/bin/service_discovery restart')
],
ignore=["rebar.lock", "apps/service_discovery_postgres/priv/migrations/"]
)
請注意,rebar.lock 會被明確忽略,這是因為它有時會在實際上並未變更時重寫,而 Tilt 沒有比較功能來驗證是否實際上發生變更,所以當 Rebar3 在本地執行時,無需執行 live_update 指示。還會忽略移轉檔,因為有其他 Docker 映像會處理這部分。
目標是 dev_release,因為我們希望能透過簡單地重新編譯與在執行中映像內重新啟動來執行 動態更新
# image to use in tilt when running the release
FROM builder as dev_release
COPY . .
RUN rebar3 as tilt release
ENTRYPOINT ["/app/_build/tilt/rel/service_discovery/bin/service_discovery"]
CMD ["foreground"]
只要檔案發生變更,live_update 指示就會在容器內執行。Rebar3 設定檔 tilt 會針對發行建置使用 dev_mode,表示要更新發行版中的編譯模組只須執行 compile 而不需要重新建置整個發行版 – 請參閱 發行版章節,以進一步瞭解 dev_mode 與發行版建置的詳細資訊 – 因此,更新指令會簡單地將 apps 目錄同步到執行中容器,執行 compile,然後重新啟動發行版。
最後,會在 TiltFile 中設定要部署的 Kubernetes 資源,並且我們設定一個監控器,以便在任何 kustomize 檔案發生變更時重新執行它。
k8s_yaml(kustomize('deployment/overlays/dev'))
watch_file('deployment/')
Tilt 內建支援 kustomize,因此我們使用 `kustomize('deployment/overlays/dev')` 來呈現 dev 覆寫並傳遞給 k8s_yaml,告訴 Tilt 要部署和追蹤哪些 Kubernetes 資源。
dev 覆寫中 kustomization.yaml 與 base 覆寫的主要差別,在於它納入了 Postgres kustomize 資源與合併至 base 資源的修補程式
bases:
- ../../base
- ../../postgres
patchesStrategicMerge:
- flyway_job_patch.yaml
fly_job_patch.yaml 用於設定 Flyway 工作,以配合 Tilt 設定運作
# For tilt we make an image named service_discovery_sql with the migrations.
# This patch replaces the image used in the flyway migration job to match.
apiVersion: batch/v1
kind: Job
metadata:
labels:
service: flyway
name: flyway
spec:
template:
spec:
initContainers:
- name: service-discovery-sql
image: service_discovery_sql
volumeMounts:
- name: migrations
mountPath: /flyway/sql
command: ["/bin/sh"]
args: ["-c", "cp /app/sql/* /flyway/sql"]
此修補程式將 Job 資源中的映像名稱變更為 service_discovery_sql,與 Tiltfile 中的第一個 custom_build 映像名稱相同。Tilt 將使用最新標籤更新映像,它將在 custom_build 中 Docker 建置命令的環境中將其設定為 $EXPECTED_REF,並重新執行 Job。這樣,在 service_discovery 在本機 Kubernetes 中執行期間,如果新增新的移轉,它將自動選取並在資料庫上執行,使我們的開發叢集與我們的本機開發保持同步。
執行 tilt 後
$ tilt up
會開啟一個主控台 UI,其中會顯示將 Tiltfile 中傳遞給 k8s_yaml 的差異資源的啟動狀態,以及與它們相關的記錄
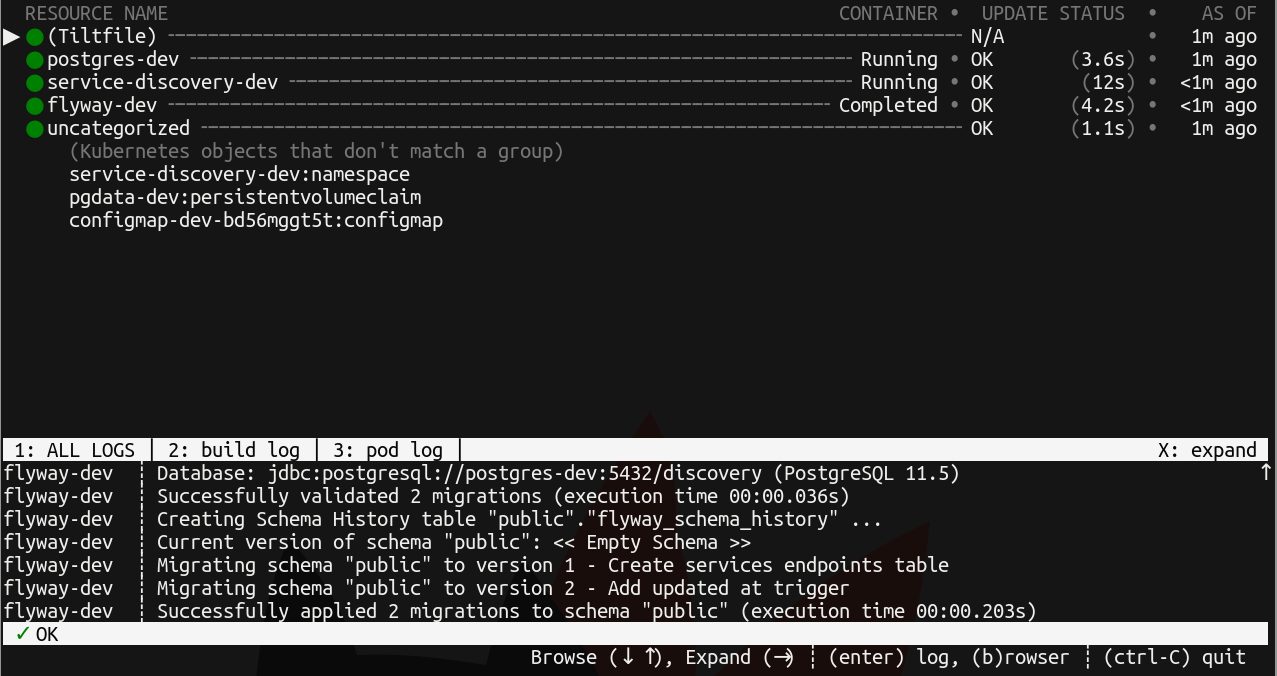
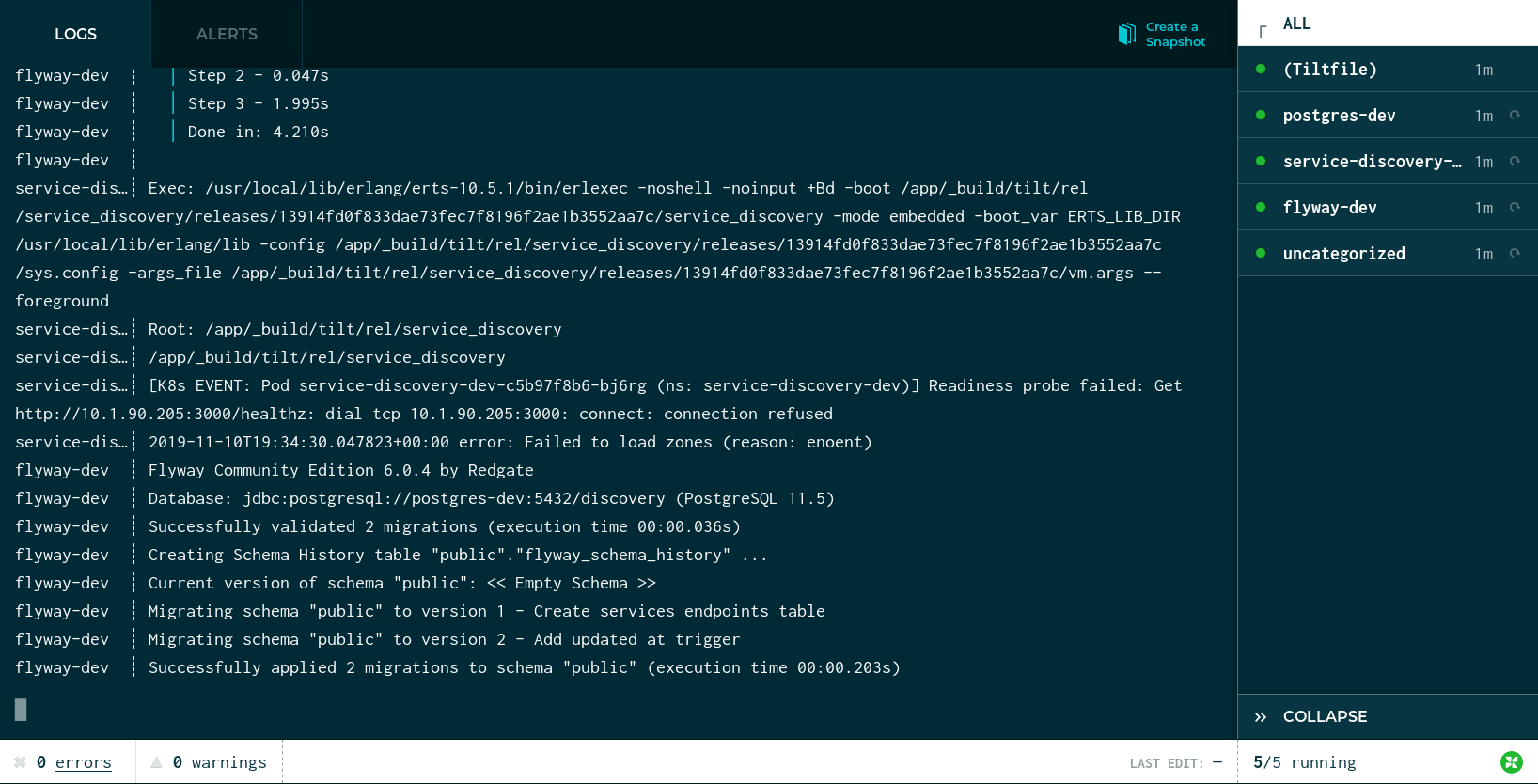
Tilt 還會自動在瀏覽器中開啟一個頁面,並顯示相同資訊
透過使用 kubectl 可以找到 service_discovery 的 IP
$ kubectl get services --namespace=service-discovery-dev
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
postgres-dev ClusterIP 10.152.183.116 <none> 5432/TCP 16m
service-discovery-dev ClusterIP 10.152.183.54 <none> 8053/UDP,3000/TCP,8081/TCP 16m
而且我們可透過 curl 和 dig 與正在執行的 service_discovery 互動,以驗證它是否正常運作
$ curl -v -XPUT http://10.152.183.54:3000/service \
-d '{"name": "service1", "attributes": {"attr-1": "value-1"}}'
$ curl -v -XGET http://10.152.183.54:3000/services
[{"attributes":{"attr-1":"value-1"},"name":"service1"}]
叢集
即將推出...
有狀態設定集
即將推出...