Erlang 與任何現有的其他程式語言之間最大的差異並非並發性,而是它的錯誤容忍性。此語言中的絕大部分內容 都專門設計用於錯誤容忍性,而監督程式則是此設計的核心部份之一。在本章中,我們將介紹監督樹的基礎知識、監督程式中的內容,以及如何在自己的系統中建構監督樹。完成後,您將能夠設定並管理系統所需的大部分狀態。
基本知識
Erlang 是一種兩層式語言。在最低層級,您會有一個函式子集。您所獲得的只是一堆資料結構、函式與模式配對,以修改並轉換它們。資料是不可變的、區域性的,如果非必要,副作用相當有限。在高層級,您有並發子集,其中管理長期性的狀態,並且在程序之間進行狀態傳遞。
函式子集相當直觀且容易學習,使用書本 簡介 中提到的任何資源都可以學習:您會取得一個資料結構,加以變更,並傳回一個新的資料結構。所有程式轉換都以函式管線的方式來處理,將函式套用至資料取得一份新的資料。這是打造您程式碼的可靠基礎。
當您必須處理副作用時,就會遇到函式語言的挑戰。您將如何採用程式組態之類的東西,並將它傳遞至整個堆疊?它將儲存在哪裡並進行修改?您如何取得本質上易變且有狀態的東西(例如網路串流),並將它嵌入至一個不可變且無狀態的應用程式中?
在大部分的程式語言中,這一切都是相當非正式且臨時的處理方式。例如,在物件導向語言中,我們傾向針對副作用的存活位置進行挑選,根據它們 領域的界限,同時可能嘗試遵循 持久性無知 或 六角形架構 等原則。
最後,你可能得到的是一種分層系統,希望在核心部分有一組純粹的特定網域實體,外表緣有一組互動機制,以及其間的幾層,其角色是協調和包裝實體之間的所有活動
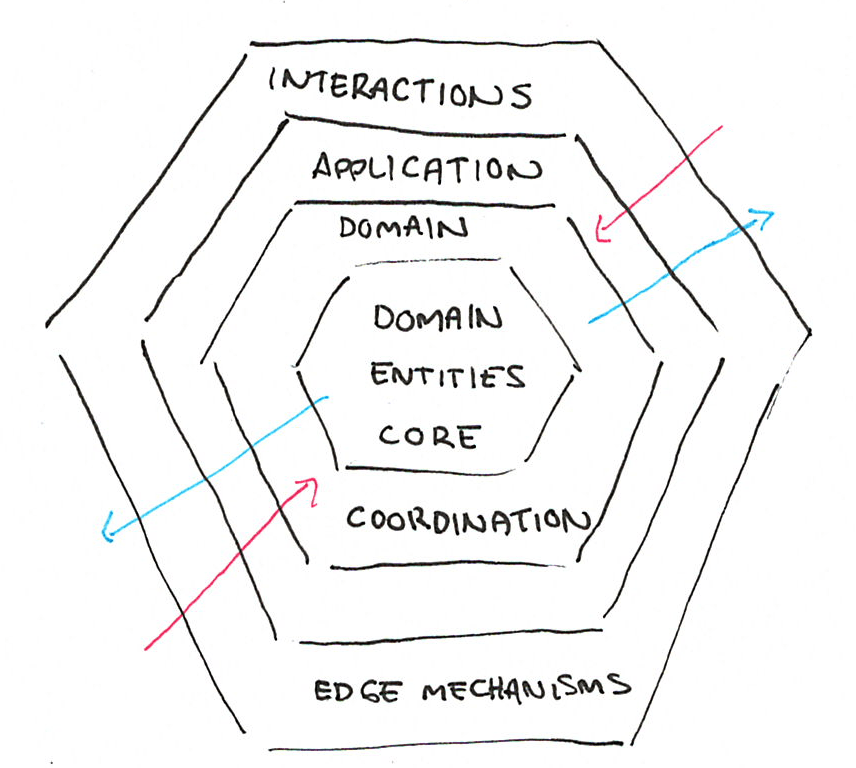
圖 1: 經常在物件導向設計中推薦的六角形架構
這種結構提供的類型通常在網域模型方面非常明確,但在互動和副作用應如何建構方面則相當模糊。如何讓連接外部服務的失敗浮現?當它來自某個事件驅動機制時,無法儲存核心網域實體上的轉換將如何影響外表緣互動?
你在物件導向系統中能執行的網域模型仍然可以在 Erlang 中執行。我們會將所有內容存放在語言的功能性子集中,通常在一個程式庫應用程式中,重新組合所有執行你需要的變更和轉換的相關模組,或在某些情況下在執行中應用程式的特定模組中。
不過,失敗和錯誤處理的豐富性將在監督結構中明確編碼。因為系統的狀態部分使用處理程序編碼,所以依賴項的結構及其各自的實例化皆會對所有人展開說明
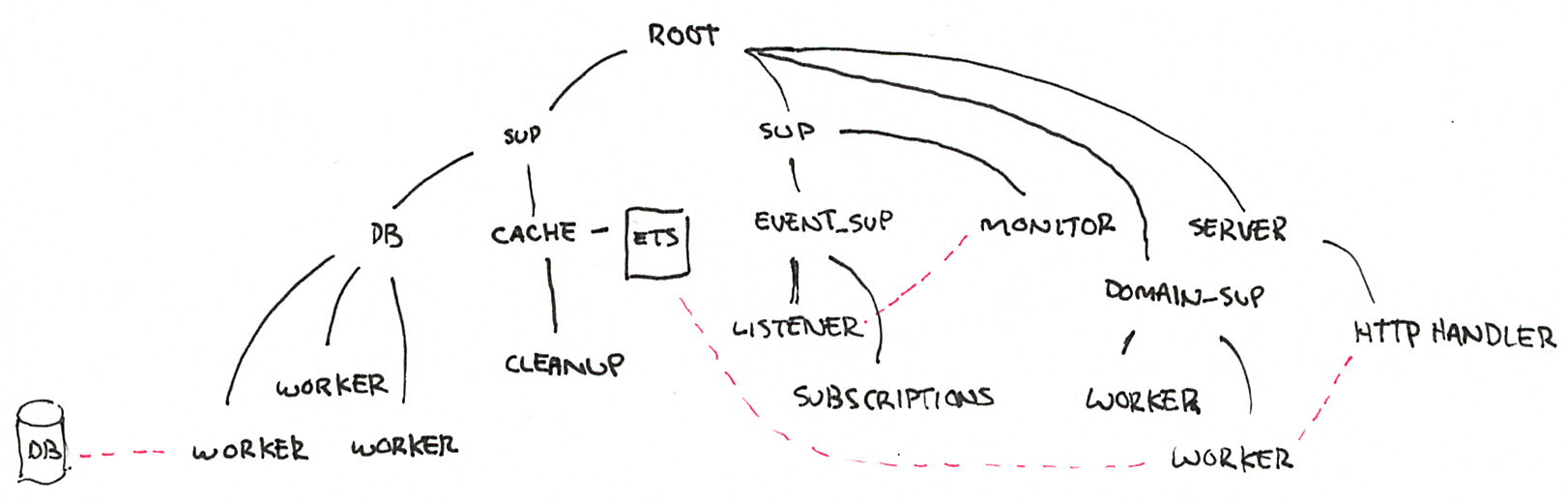
圖 2: 範例監督樹
在這種結構中,所有處理程序從左到右,按深度優先啟動。這表示在快取處理程序和 ETS 表格 啟動之前,資料庫的監督結構(及其所有工作人員)必須先啟動。類似地,HTTP 伺服器及其處理常式啟動之前,整個商業網域子樹已經建立,而且由於它依賴快取表格,我們將同樣確保此表格(和資料庫工作人員)準備就緒。
這個監督結構定義了版本如何啟動,但也會定義它如何關閉:深度優先,從右到左。而且更進一步,每個監督者都可以設定自己對子項失敗的策略和容忍度。這表示它們還定義了系統中允許或不允許哪些類型的 部分失敗。如果無法與資料庫通話,節點是否仍然要執行?它可能應該要,但如果快取變得不可用,它無法持續運作。
簡而言之,當功能性資訊可以用於特定網域的處理時,狀態、事件和與外界的互動流在有狀態組件中被編纂和說明,為我們提供處理錯誤和初始化的全新方式。
我們等等會了解如何執行此操作,但首先,讓我們回顧一下監督者如何運作。
監督者包含哪些內容
表面上來說,在 Erlang/OTP 中,監控器是最簡單的行為之一。它們接受單一 init/1 回呼,而這也差不多就是監控器的全部內容了。這個回呼用於定義每個監控器的子節點,並設定某些基本原則,以便監控器對各種失敗做出反應。
有 3 種類型的原則需要處理
- 監控器類型
- 子節點的重新啟動原則
- 可接受的故障頻率
每一項在孤立狀態下都非常簡單,但若要選出合適的項目,就可能會變得有點棘手。讓我們從監控器類型開始
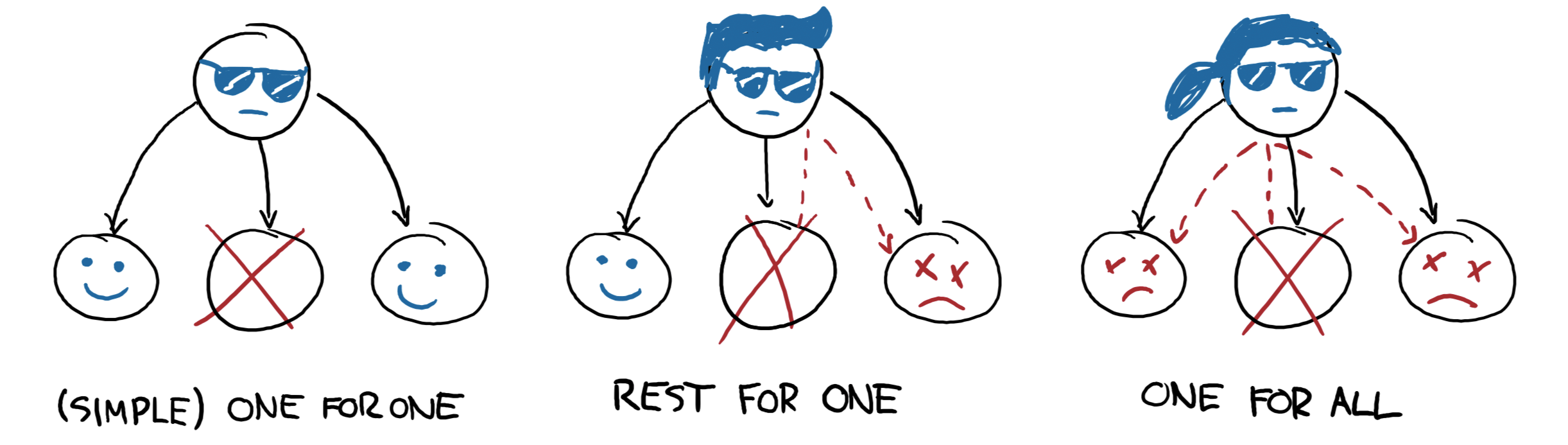
圖 3: 三種類型的監控器
策略有 3 種類型
one_for_one(一對一),指出各個子節點彼此獨立。如果有一個子節點掛掉,其他子節點則不需要任何取代或修改。simple_one_for_one(簡化一對一)在所有子節點都是同類型的情況下(例如員工池),是one_for_one的特殊化形式,速度較快,而且負擔也較輕。
rest_for_one(其餘一對一)編碼了監控器子節點之間的線性依賴性。如果其中一個掛掉,所有在 之後所啟動的子節點都必須重新啟動,而之前啟動的子節點則不需要重新啟動。在流程C仰賴流程B,而B仰賴流程A的情況下,rest_for_one策略可以有效地編碼其依賴性結構。one_for_all(一對全部)是一個策略,只要有任一個子節點掛掉,那麼所有子節點都必須重新啟動。這是您在所有子節點之間有著強烈相互依賴關係時,會想要使用的監控器類型;如果其中任一個重新啟動,其他子節點就沒有方法能輕易還原,因此也應該重新啟動。
這些策略實際上都是關於,監控器子節點之間如何傳播錯誤。接下來要考慮的部分,則是各個失敗的流程,應如何自行處理在訊號傳播後的監控器。
| 重新啟動原則 | 在正常退出時 | 在異常退出時 |
|---|---|---|
| 永久 | 重新啟動 | 重新啟動 |
| 暫時 | 保持死亡 | 重新啟動 |
| 暫時 | 保持死亡 | 保持死亡 |
這讓您可以說明,預期某些流程永遠不會停止(永久),預期某些流程會停止(暫時),以及預期某些流程會失敗(暫時)。
我們可以設定的最後一點設定,就是允許重新啟動的頻率。這將透過 intensity(強度)和 period(時間)兩個參數來處理,它們分別代表已發現多少崩潰,以及這些崩潰發生於多少秒內。然後,我們可以指定一個監控器每小時只能容忍一次崩潰,或者如果我們希望,讓它每秒崩潰十幾次。
這是您宣告監控器的方式
-module(myapp_sup).
-behaviour(supervisor).
%% API
-export([start_link/0]).
%% Supervisor callbacks
-export([init/1]).
-define(SERVER, ?MODULE).
start_link() ->
supervisor:start_link({local, ?SERVER}, ?MODULE, []).
init([]) ->
{ok, {{one_for_all, 1, 10}, [ % one failure per 10 seconds
#{id => internal_name, % mandatory
start => {mymod, function, [args]}. % mandatory
restart => permanent, % optional
shutdown => 5000, % optional
type => worker, % optional
modules => [mymod]} % optional
]}}.
在這裡,你可以一次定義多少個子層端 (simple_one_for_one 除外,它會預期說明範本)。你可以指定其他引數給子層,包括 shutdown,為適當終止子層端提供幾毫秒的等待時間 (或 brutal_kill 以立即將其終止),以及定義程序是 worker 還是 supervisor。此 type 欄位以及 modules 僅在使用版本進行動態程式碼升級時使用,後者通常可以忽略且保持其預設值。
這就是所需要的全部。讓我們看看如何實際應用。
嘗試自己的監督者
讓我們嘗試向應用程式新增一個具有工作人員的監督者,執行本質上就是世界上最繁重的 Hello World。我們將為其建立一個完整的版本
$ rebar3 new release hello_world
===> Writing hello_world/apps/hello_world/src/hello_world_app.erl
===> Writing hello_world/apps/hello_world/src/hello_world_sup.erl
===> Writing hello_world/apps/hello_world/src/hello_world.app.src
===> Writing hello_world/rebar.config
===> Writing hello_world/config/sys.config
===> Writing hello_world/config/vm.args
===> Writing hello_world/.gitignore
===> Writing hello_world/LICENSE
===> Writing hello_world/README.md
$ cd hello_world
你應當會認知版本結構,其中所用的全部 OTP 應用程式都位於 apps/ 子目錄中。
開啟 hello_world_sup 模組,並確認其看起來像這樣
%%%----------------------------------------------------------
%% @doc hello_world top level supervisor.
%% @end
%%%----------------------------------------------------------
-module(hello_world_sup).
-behaviour(supervisor).
-export([start_link/0]).
-export([init/1]).
-define(SERVER, ?MODULE).
start_link() ->
supervisor:start_link({local, ?SERVER}, ?MODULE, []).
init([]) ->
SupFlags = #{strategy => one_for_all,
intensity => 0,
period => 1},
ChildSpecs = [
#{id => main,
start => {hello_world_serv, start_link, []}}
],
{ok, {SupFlags, ChildSpecs}}.
這會建立一個單一工作人員,這個工作人員將會位於模組 hello_world_serv 中。這將會是一個簡單的 gen_server 什麼都不做,僅使用其 init 函數
-module(hello_world_serv).
-export([start_link/0, init/1]).
start_link() ->
gen_server:start_link(?MODULE, [], []).
init([]) ->
%% Here we ignore what OTP asks of us and just do
%% however we please.
io:format("Hello, heavy world!~n"),
halt(0). % shut down the VM without error
這個檔案僅啟動一個 OTP 程序,輸出 Hello, heavy world!,接著關閉整個虛擬機器。
讓我們建置一個版本並看看會發生什麼事
$ rebar3 release
===> Verifying dependencies...
===> Compiling hello_world
===> Starting relx build process ...
===> Resolving OTP Applications from directories:
/Users/ferd/code/self/adoptingerlang/hello_world/_build/default/lib
/Users/ferd/code/self/adoptingerlang/hello_world/apps
/Users/ferd/bin/erls/21.1.3/lib
===> Resolved hello_world-0.1.0
===> Dev mode enabled, release will be symlinked
===> release successfully created!
現在我們可以啟動它了。我們將使用 foreground 引數,這表示我們將啟動版本以查看其所有輸出,但在非互動模式 (沒有 shell) 下執行。
$ ./_build/default/rel/hello_world/bin/hello_world foreground
<debug output provided by wrappers bundled with Rebar3>
Hello, heavy world!
這裡發生的事是,這些工具在 /_build/default/rel/hello_world/bin/hello_world 產生一個指令碼。這個指令碼將一堆東西整合在一起,確保你的版本使用所有正確的組態與環境值啟動。
一切從啟動虛擬機器開始,最後在 Erlang 本身中衍生根程序。kernel OTP 應用程式啟動,然後在組態資料中看到它必須啟動 hello_world 應用程式。
這透過呼叫 hello_world_app:start/2 來完成,而它反過來呼叫 hello_world_sup,這會啟動 hello_world_serv 程序,而該程序會輸出文字,然後對 VM 下達強制呼叫,告訴它關機。
這就是我們剛剛所做的。監督者僅啟動並重新啟動程序;它們很簡單,但它們的力量來自於它們如何組成並用於建構系統。
建構監督樹
監督者最複雜的部分不是其宣告,而是其組成。它們是處理複雜任務的簡單工具。在本節中,我們將介紹為什麼監督樹能運作,以及如何最佳化建構這些樹以最大化其效益。
監督者運作的方式
人人聽過「試著關機再開機」的一句普遍除錯方針。它出乎意料地常常奏效,而 Erlang 監督樹就是依循此原則而運作的。當然,重新啟動無法解決所有臭蟲,但已經可以涵蓋很多。
重新啟動有效的原因,是由於生產系統中遇到的臭蟲性質。為討論此點,我們必須參考 Jim Gray 在 1985 年創造的術語:波耳臭蟲 (Bohrbug) 和 海森堡臭蟲 (Heisenbug)。基本而言,波耳臭蟲是一個穩定、可觀察,且易於重複發生的臭蟲。它們往往相當容易理解。相對來說,海森堡臭蟲的行為不可靠,僅在特定條件下顯現,並可能因為單純的觀察嘗試而消失。例如,並發臭蟲在使用偵錯器時會消失是出了名的,因為偵錯器可能會強制系統中的每個操作序列化。
海森堡臭蟲是這些令人討厭的臭蟲,發生機率可能在千分之一、百萬分之一、十億分之一或兆分之一。一旦看到有人列印出多頁程式碼,並拿一堆標記筆狠寫特寫一番,那麼你可以知道他一直在想辦法找出海森堡臭蟲。
在定義這些術語之後,讓我們來看看在產品環境中找出臭蟲應該有多容易
| 功能類型 | 可重複 | 暫態性 |
|---|---|---|
| 核心功能 | 容易 | 困難 |
| 次要功能 | 容易(常常忽略) | 困難 |
如果系統核心功能中有波耳臭蟲,那麼在進入產品環境之前通常可以很輕鬆地找到。由於它們具有可重複性,而且常常出現在關鍵路徑上,所以遲早你會遇到它們,並且在發布前修復它們。
發生在次要、較少使用的功能中的臭蟲,經常是一個中獎與否的問題。每個人都承認,修復軟體中所有臭蟲是一場越來越難贏的硬仗;清除所有小瑕疵會隨著時間推移,花費不成比例的時間。這些次要功能通常較不受到關注,原因可能是使用它們的客戶較少,或是它們對客戶滿意度的影響較不重要。或者可能是它們只是被排程在較晚的時間,最後期限的延誤導致它們的工作優先順序降低。
在開發過程中幾乎不可能找到海森堡臭蟲。正式證明、模型驗證、窮舉測試或基於屬性的測試等出色技術,可能會提高找出其中某些或所有臭蟲的機率(取決於所使用的方式),但坦白說,除非手邊的工作極其關鍵,否則我們很少使用這些技術。一個發生機率低於十億分之一的問題,需要相當多的測試和驗證才能找出,而如果你真的看過這個問題,你很可能無法再靠運氣重新產生它。
因此,讓我們來看一下前述的臭蟲類型表格,但重點放在它們在產品環境中發生的機率
| 功能類型 | 可重複 | 暫態性 |
|---|---|---|
| 核心功能 | 永遠不應發生 | 持續發生 |
| 次要功能 | 經常發生 | 持續發生 |
首先,核心功能中容易重複產生的錯誤不應該出現在正式作業中。如果出現了,您基本上發送了一個有問題的產品,而且無論重新啟動或提供多少支援,都無法協助您的使用者。這些需要修改程式碼,而且可能是產生它們的組織中某些根深蒂固的問題所造成的。
次要功能中的可重複錯誤通常會進入正式作業。這通常是因為沒有時間好好測試或沒有進行測試,但是還有很大的可能性是,在進行部分重構時,次要的功能經常被忽略,或是負責設計這些功能的人員沒有完全考量這些功能是否能與系統其他部分協調整合。
另一方面,暫時性錯誤會一直出現。提出這些術語的 Jim Gray 表示,在某組客戶網站記錄的 132 個錯誤中,只有一個是波耳蟲錯誤。在正式作業中遇到的 131/132 的錯誤往往是海森堡錯誤。這些錯誤很難找出;如果真的像統計錯誤,可能百萬次中才會出現一次,只要系統負載夠重,這些問題隨時都會觸發;每十億次才會出現一次的錯誤會在每秒處理 100,000 個要求的系統中每 3 個小時出現一次,同樣的,每百萬次才會出現一次的錯誤會在這樣的系統中每 10 秒出現一次,但在測試中它們的發生頻率仍然很低。
有很多錯誤,如果處理不當,會有很多失敗。讓我們重新整理表格,但現在我們考慮的是重新啟動是否可以處理這些錯誤
| 功能類型 | 可重複 | 暫態性 |
|---|---|---|
| 核心功能 | 否 | 是 |
| 次要功能 | 視情況而定 | 是 |
對於核心功能的可重複錯誤,重新啟動是無用的。對於在較不常使用的程式碼路徑中的可重複錯誤,則視情況而定;如果這個功能對極少數使用者來說很重要,那麼重新啟動不會有太大的作用。如果這是一個每個人都在使用,但並不特別重視的次要功能,那麼重新啟動或完全忽略錯誤可能會很有用。
但對於暫時性錯誤,重新啟動非常有效,而且是您在執行期間會遇到的絕大多數錯誤。由於它們難以再現,因此它們的出現通常取決於系統狀態的非常具體環境或交織運作,而且它們的出現傾向於只發生在所有作業中極少數的一部分中,因此重新啟動往往會讓這些錯誤完全消失。
主管人員允許系統中受到此類錯誤影響的部分還原到已知的穩定狀態。一旦您還原到此狀態,再次嘗試不太可能會碰到導致第一個錯誤的同樣奇怪情境。這樣,本來可能導致大災難的情況,現在變成系統的小障礙,使用者很快就會學到可以忍受。
這與保證有關
Erlang 監督程式及其監督樹中一個非常重要的部分在於啟動階段是同步的。每個 OTP 處理程序在啟動中會有一段時間能執行自己的事,防止其他手足或表兄弟的整個開機順序都上場。如果處理程序在那時中止,會重試,並一直重試到成功,或是失敗的次數太多。
這時人們經常犯一個非常普遍的錯誤。在監督程式重啟已中斷的子處理程序之前,並無緩衝期或冷卻期。當人們寫一個網路型應用程式,在這個初始化階段嘗試建立連線,而遠端服務中斷時,該應用程式會在經過太多次徒勞無功的重啟後無法開機。然後該系統可能會關閉。
許多 Erlang 開發人員最後都贊成建立一個有冷卻期的監督程式。這種想法基於一個簡單的理由是錯誤的:一切都是保證。
要重啟一個處理程序是要讓它回到一個穩定的已知狀態。從那裡開始,就能重試。如果初始化不穩定,監督程式幾乎等於沒有。一個已初始化的處理程序應該無論發生什麼事都能保持穩定。這樣,當它的手足及表兄弟在以後啟動時,它們可以放心地開機,因為它們知道在它們之前開機的系統其他部分都很健康。
如果你沒有提供那個穩定的狀態,或者你會異步啟動整個系統,你從這種結構得到的幫助將比迴圈中的 try ... catch 提供的少很多。
在初始化階段,受監督的處理程序提供的是保證,而不是盡力。這表示當你寫一個資料庫或服務的用戶端時,你不需要在初始化階段中建立連線,除非你準備好說明無論發生什麼事,連線都會一直可用。
舉例來說,如果你知道資料庫在同一個主機上,而且應該在你 Erlang 系統開機前開機, puedes 強制在初始化期間連線。然後重啟就會奏效。萬一發生某些令人費解且出人意料的事,破壞了這些保證,節點就會中斷,這是理想的結果:因為啟動系統的先決條件沒有滿足。這是系統級的斷言失敗。
另一方面,如果你的資料庫在遠端主機上,你應該預期連線會失敗。在這種情況下,你可以在用戶端處理程序中唯一能做出的保證是,你的用戶端能夠處理要求,而不是它會與資料庫傳輸。它可以在網路中斷時針對所有的呼叫傳回 {error, not_connected},舉例來說。
然後,可以採用你認為最佳的任何冷卻期或後退策略,重新連線資料庫,而不會影響系統的穩定性。可以在初始化階段中嘗試把這當作最佳化,但是如果任何東西中斷了,該處理程序應該能夠以後再重新連線。
如果預期外部服務會發生故障,請勿將其視為系統的保證。我們在此處理現實世界,外部依賴項的故障始終是選項。
當然,如果呼叫用戶端程式庫和流程沒有預期在沒有資料庫的情況下執行,它們就會出現錯誤。這是不同問題領域中完全不同的問題,但並非總是無法解決。例如,假設用戶端是 Ops 人員的統計服務,則呼叫該用戶端程式碼可以輕易忽略錯誤,而不會對整體系統造成不利影響。在其他情況下,可以將事件佇列新增到用戶端之前,以避免事情變糟時遺失狀態。
初始化和監督方式的區別在於,是用戶端呼叫程式決定可以容忍多少故障,而不是用戶端本身。在設計容錯系統時,這是一個非常重要的區別。是的,監督員是關於重新啟動,但它們應該是重新啟動到穩定的已知狀態。
樹木生長
在建構 Erlang 程式時,任何感覺脆弱且應該允許失敗的事情都必須深入層級結構,而穩定且關鍵且需要可靠的事情需要在較高的層級。監督結構允許編碼部分故障和故障傳播,所以我們必須妥善思考所有這些事情。我們再次檢視我們的範例監督樹狀圖
如果 DB 子樹中的工作者死亡,並且 DB 是具有 one_for_one 策略的監督員,那麼我們編碼每個工作者都會被允許獨立於彼此失敗。另一方面,如果 event_sup 具有 rest_for_one 策略,我們就在系統中編碼處理訂閱的工作者如果事件聆聽器死亡,則必須重新啟動;我們說有直接依賴性。
由默示,還有一個聲明,指出事件處理子樹不會直接受到資料庫影響,只要它已設法在某個時間點成功啟動即可。
閱讀這個監督樹狀圖就像系統故障的排程和地圖。除非特定於網域的工作者可用,否則 HTTP 伺服器不會啟動,而 HTTP 處理器失敗不會對資料庫快取造成任何可能造成危害的行為。當然,如果 HTTP 處理器依賴於網域工作者,而該工作者依賴於快取的 ETS 資料表,而該資料表消失了,那麼所有這些流程都可能同時終止。
這裡真正有趣的是,我們可以一眼看出即使未知的故障也可能會如何影響我們的系統。我不需要知道為什麼資料庫工作者可能會失敗,無論是因為斷線、資料庫死亡還是協定實作中的錯誤;我知道無論如何,這都應該保留快取,並可能讓我進行陳舊的讀取,直到資料庫子樹再次可用。
這時,結合了子體的重新啟動策略,以及監視者可接受的錯誤發生頻率,就能派上用場了。若所有作業系統和其監視者標記為 permanent,則系統可能發生頻繁崩潰故障,殃及整個節點。不過,你可以耍一個小巧妙
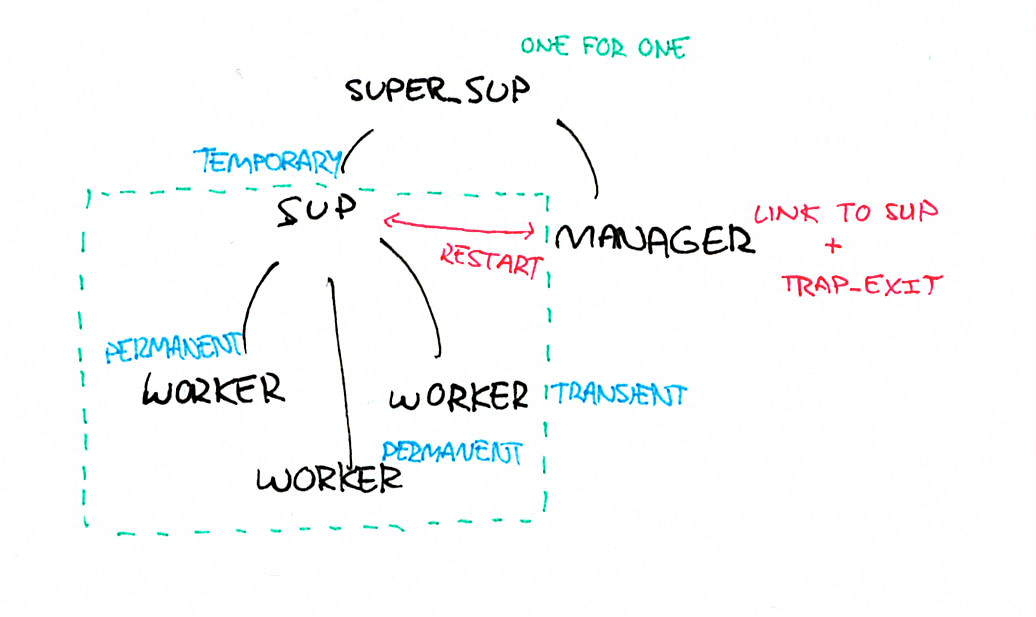
圖 4:管理者作業模式
- 標記作業系統為
permanent或transient,這樣一來,系統發生故障後就會重新啟動 - 將作業系統的直接監視者(方格中的)標記為
temporary,如此系統發生故障,就會放棄且不會重新啟動 - 在上方加入新的監視者(此處可使用任何想要的功能),但要將此功能設定為
one_for_one。 - 在新的監視者下方加入新的程序(
temporary監視者的兄弟元件)。將此程序 連結 至舊有監視者。這個元件即為 manager。
可以用 temporary 監視者容忍可接受的重新啟動頻率。舉例來說,系統可以表示一個作業系統每兩分鐘死亡一次是正常的。不過,若超過此臨界值,則表示發生嚴重問題,我們想在情況惡化、造成節點不穩定之前,先停止重試。監視者會關閉,由於其為暫時的,因此超級監視者(方格上方)只會待在那裡,什麼事都不做。
接著,管理者可以查看 sup 監視者是處於運作中或關閉狀態,並針對是否重新啟動套用它想要的任何功能:使用指數遞減、等到 斷路器 未跳脫、等到外部服務登錄檔表示依賴的服務回復正常,或詢問使用者要如何處理。接著,管理者可以要求其母體監視器重新啟動暫時監視者,而暫時監視者將會重新啟動其作業系統。
這是 Erlang 中少數幾個 設計模式 之一。由於聰明的系統會犯下愚蠢的錯,所以我們希望監視器越簡單又可預測越好。管理者就是我們在監視器中加入大腦,並做出更明智決定的方法。這讓我們可以將暫時錯誤的政策與主要錯誤或持續故障(無法單靠重新啟動來處理)的政策分開。
註
可以依你的需求調整此模式。舉例來說,作者已使用以下兩種其他變體進行重新啟動管理
- 多個監視樹互相嵌套,每個都代表實體裝置的作業池。每個實體裝置都被允許發生故障、離線或斷電。管理程序將定期將運作中的子樹與站外設定服務對比。接著,啟動所有遺失的子樹,並關閉所有不再存在的子樹。如此一來,管理者便可在處理棘手的硬體故障情境時的重新啟動之外,同時處理執行階段的設定同步。
- 管理員並未執行任何動作。但隨 Erlang 發行的發行版內附一個腳本,供操作員呼叫。腳本會傳送訊息至管理員,要求管理員重新啟動遺失的子樹。之所以使用此變異方法,是因為子樹只在罕見情況下會死掉(整個區域的儲存空間遭到關閉)且不會想要讓系統中的其他部分中斷,不過在復原時,操作員可以透過此方式重新啟用流量。
雖然要讓這類功能建立於一般監管程式會很困難,但管理員可以輕易提供客製化解決方案所需的彈性。
我們建議您可以進行一項練習,將系統畫在白板上,然後繪出其監管樹。遍歷所有工作常式和監管程式,然後詢問下列問題
- 如果這個中斷,是否會沒關係?
- 其他程序是否應該與這個一起終止?
- 這個程序是否依賴於其他東西,這些東西在重新啟動後會變成很奇怪?
- 這個監管程式可以承受多少次崩潰?
- 如果系統的這個部分完全出問題,其他部分是否應該繼續執行,或者我們應該放棄?
與您的團隊討論這些問題。隨機更換監管程式,調整策略和政策。新增或移除監管層級,同時在某些情況下,新增管理員。
不定期地重複這項練習,最終透過在執行中節點上終止 Erlang 程序,執行一些混沌工程,了解其是否按照您認為的方式執行和復原(當然,您也可以對整個節點執行混沌工程,因為這更常見)。最終您會獲得一段容錯的程式碼。您還會打造一支對系統中內建的錯誤語意擁有深入了解的團隊,並具備事物在不可避免崩潰時應如何解析的良好心智模型。這會極具效益。