您現在可能對 Erlang 專案的架構方式有相當程度的了解。只要具備關於語言基本知識的任何指南,您就可以開始進行。然而,Erlang 現有文件中有一些複雜的主題目前尚未得到充分說明。在本章中,我們將通過處理 Unicode、時間和 SSL/TLS 配置的任務來提供指導。
請注意,這三個主題本身就很複雜。雖然我們將對其中每一個主題提供一些背景資訊,但您並不會立即成為處理它們的專家,它只是有助您了解必須知道多少複雜性,才能避免犯下重大錯誤。
處理 Unicode
Erlang 在字串處理方面聲譽不佳。這主要來自於它沒有專用的字串類型,而且多年來,除了社群函式庫之外,沒有適當的 Unicode 支援。儘管前者沒有改變,但這種方法有一些優點,而後者已在最近的 Erlang 版本中得到解決。
Unicode 背景資訊
簡而言之,Unicode 是一組關於如何在電腦中處理文字的標準,而與使用者的語言無關(這是指真正的語言,而不是程式語言)。它已成為一個十分龐大的規格說明,有關於所有種類細節的許多極其複雜的考量,而且開發人員經常會因此而感到迷失。
即使不完全了解 Unicode,您也能瞭解 足夠多的內容,以產生效益和避免犯下所有顯而易見的錯誤。一開始我們先介紹一些術語。
- 字元:「字元」一詞在 Unicode 中定義得很模糊。每次您看到「字元」一詞時,請想像與您交談的人正在使用一個非常抽象的術語,它可以代表任何東西,從給定字母表中的字母、某些繪圖(例如表情符號)、變音符號或字母修飾符(例如
¸和c,它變成ç)、控制序列(例如「退格」)等等。這大多是一種常見但不太精確的方式,指涉文字片段,而不應賦予其太多意義。Unicode 有著它自己更好且更精確的定義。 - 編碼點:Unicode 標準定義了一個大型清單中所有可用的基本基本「字元」(以及更多),每個都有唯一的識別碼。該識別碼是 編碼點,通常表示為
U+<16 進位數字>。例如,「M」的編碼點為U+004D,而 ♻ 的編碼點為U+267B。您可以在 Unicode 表格 中看到完整清單。 - 編碼:雖然編碼點只是可供您查找的索引的整數,但不足以代表程式語言中的文字。在歷史上,許多系統和程式語言使用位元組(
0..255)來代表語言中所有有效的字元。如果您需要更多字元,則必須切換語言。為了相容於各種系統,Unicode 定義了 編碼,讓人們可以使用各種方案來表示編碼點序列。UTF-8 是最常見的編碼,對所有內容都使用位元組。它的表示法與 ASCII 或 Latin-1 的基本結構相同,因此在拉丁語和日耳曼語中變得非常流行。UTF-16 和 UTF-32 兩個替代方案的表示範圍較寬(16 或 32 位元)。 - 編碼單元:編碼單元指定給定編碼點在給定編碼中的編碼方式。每個編碼點在 UTF-8 中占用了 1 到 4 個編碼單元。例如,
F在 UTF-8 中只占用了46作為編碼單元,0046在 UTF-16 中,00000046在 UTF-32 中。相較之下,©的編碼點為U+00A9,但在 UTF-8 中可表示為 兩個 編碼單元(C2和A9),在 UTF-16 和 UTF-32 中可表示為一個編碼單元(分別為00A9和000000A9)。 - 字形:字元的圖形表示。例如,
U+2126為「歐姆符號」,表示為Ω,而U+03A9為「希臘大寫字母歐米茄」,也表示為外觀相似的Ω。在某些 字體 中,它們會相同,在某些字體中則不會。同樣地,字母「a」可能可以用看起來像「а」或「α」的字形表示。有些編碼點沒有相關的字形(例如「退格」),而有些字形可以用於表示多個編碼點的 連字(例如ae的æ)。 - 音位群集:迄今為止所提到的所有術語都與非常抽象的概念有關。Unicode 有趣的東西就像 組合符號 和將多個編碼點聯結成一個「字元」的方式。這可能會變得超級令人困惑,因為使用者認為的字元和程式設計師認為的字元間不相同。音位群集 是指「使用者視為單一字元的文字單元」的術語。例如,字母「ï」由兩個編碼點組成:拉丁小寫字母
i(U+0069) 和一個組合變音符號 (¨為U+0308)。因此,對程式設計師來說,這看起來像兩個編碼點,用 UTF-8 編碼為 3 個編碼單位。然而,對使用者來說,他們期望按一下「清除鍵」就能移除變音符號 和 字母「i」。
這些東西很多,但了解這些是很重要的。程式設計師如何撰寫字元和最終如何呈現在使用者眼前之間沒有直接關係。
一個特別有趣的範例是 阿拉伯連字 BISMILLAH AR-RAHMAN AR-RAHEEM,它是一個單一編碼點 (U+FDFD),但在圖形上表示為「﷽」。這是目前 Unicode 標準中最寬的「字元」。這代表了一個完整的阿拉伯語句子,並新增到該標準,因為事實證明,這是多個烏爾都語文件中的法律要求,而其鍵盤配置無法輸入阿拉伯語。它是搞亂使用者介面人員的偉大 Unicode。
大多數語言都有圖形(和邏輯)表示法不等於建立最終字元的底層碼的問題。這些存在於各種語言的所有可能的連字和「字元部分」組裝中,但對於表情符號,也可以透過組合個別個體來組成一個家庭:👩👩👦👦 是由 4 個具有組合符號的元件組成的家庭:👩 + 👩 + 👦 + 👦,其中 + 是兩個女人和兩個男孩之間的特殊組合符號(零寬繋字元)(如果您正在舊瀏覽器上查看此文件,使用舊字型,或正在閱覽本書的 PDF 版本,那麼您可能會看到四個人,而不是一個家庭。)如果您逐位元組或逐編碼點地使用該順序,您將會破壞家庭並改變文字的語意含義。
如果您在傳統上十分支援地區和所有語言規則的文字編輯器(例如 Microsoft Word,我們所知僅有的少數幾個應用程式能自動處理半形空格和不換行空格,按語言要求處理)中編輯文字,在 👩👩👦👦 上按 Backspace 將會刪除整個家族為一個單位。如果您在 FireFox 或 Chrome 中執行這項動作,刪除該一個「字元」將會花費您 7 回鍵:針對每個人各按一次,以及針對每個零寬度結合字元各按一次。Slack 會將它們視為一個單一字元,而 Visual Studio Code 則會像瀏覽器一般(即使兩個都是電子應用程式),且 notepad.exe 或許多終端機模擬器會將它們擴充為 4 個人,並隱式刪除零寬度結合標記。
代表不論您使用哪一種程式語言,如果字串看起來像是您能以位置或透過某些索引來擷取「字元」的陣列,您很可能會遇到嚴重問題。
比這更糟的是,有些「字元」在 Unicode 中有兩個以上的可接受編碼。字元 é 可以透過編碼單一碼點(U+00E9)來產生,或作為字母 e(U+0065)和 ´(U+0301)的組合產生。這在邏輯上將會是法文中相同的字母 é,但使用這兩個不同形式的兩個字串比較時不會相等。因此 Unicode 引入了 正規化 等觀念,其指定如何根據四個可能的標準(NFC、NFD、NFKC 和 NFKD)強制轉換字串的表示方式(如果您不知道要使用哪一個,請堅持使用 NFC)。
排序字串也會引入 校對 等觀念,這在排序時需要知道目前使用的語言。
簡單來說,要讓您的程式充分支援 Unicode,不論您使用哪一種程式語言,您都必須將字串當成一種不透明資料類型來處理,您只能透過具備 Unicode 認知能力的函式庫獨家處理。其他一切都是您在處理 位元組序列 或 碼點序列,而最終也可能在人類可讀取的層級上意外讓某些東西中斷。
在 Erlang 中處理字串
Erlang 對字串的支援起初看起來有點怪:沒有專屬的字串類型。不過,考量到 Unicode 的所有複雜性,這其實並沒有那麼糟糕。通常與僅 一種 字串類型共事就像與 沒有 字串類型共事一樣複雜,這是由於所有可能的替代表示方式所致。
當前使用具備反映多種編碼可變字串類型的程式語言的人們現在可能會覺得很好,但您會發現 Erlang 擁有相當良好的 Unicode 支援,綜合考量所有因素來看,只缺少校對。
資料類型
在 Erlang 中,您必須留意下列可能的字串編碼
"abcdef":一個字串,直接由清單中的 Unicode 碼點組成。這表示如果你在你的 Erlang 指令殼中寫下[16#1f914],你將會完全獲得字串"🤔",與編碼無關。這是一個單向串列。<<"abcdef">>作為一個二進制字串,是<<$a, $b, $c, $d, $e, $f>>的縮寫。這是作為二進制轉換的古老標準 Latin1 整數清單。預設情況下,此文字格式不支援 Unicode 編碼,如果你放置一個過大的值(例如16#1f914)在裡面,在你的原始檔中宣告一個像是<<"🤔">>的二進制,你將會看到一個溢位,以及最後的二進制<<20>>。這是用 Erlang 二進制(實際上是一個不可變的位元組陣列)來實作的,目的是為了處理任何類型的二進制資料內容,即使它不是文字。<<"abcdef"/utf8>>作為一個二進制 Unicode 字串,編碼為 UTF-8。這個會用來支援表情符號。它仍然是用 Erlang 二進制來實作的,但/utf8建構函式確保適當的 Unicode 編碼。<<"🤔"/utf8>>傳回<<240,159,164,148>>,這是用 UTF-8 表示思考表情符號的正確順序。<<"abcdef"/utf16>>作為一個二進制字串,編碼為 UTF-16 的 Unicode。<<"🤔"/utf16>>傳回<<216,62,221,20>><<"abcdef"/utf32>>作為一個二進制字串,編碼為 UTF-32 的 Unicode。<<"🤔"/utf32>>傳回<<0,1,249,20>>["abcdef", <<"abcdef"/utf8>>]:這是一個稱為「IoData」的特殊清單,可以支援多種字串格式。你的清單可以像往常一樣是碼點,但你會希望所有二進制都是相同的編碼(最好是 UTF-8),以防止編碼混在一起的問題。
如果你想使用 Unicode 內容,你將希望使用 Erlang 中不同的與字串有關的模組。
第一個是 string,它包含一些函式,例如 equal/2-4,用於處理字串比較,同時處理大小寫敏感性和正規化;find/2-3 用於尋找子字串;length/1 用於取得字元組群的數目;lexemes/2 用於在某些模式上分割字串;next_codepoint/1 和 next_grapheme/1 用於消耗字串的位元;replace/3-4 用於替換;to_graphemes/1 用於將字串轉換為字元組群清單;最後是 lowercase/1、uppercase/1 和 titlecase/1 等函式,用於控制大小寫。該模組中仍包含更多內容,但這應該具有代表性。
您還將需要使用 unicode 模組來處理跨字串格式、編碼和正規化格式的所有轉換。正規表示式模組 re 完美處理 unicode(只需在其選項清單中傳入 unicode 原子,並讓您在傳入 ucp 選項時使用 通用字元類型 。最後,file 和 io 模組都支援特定選項,以使 unicode 正常運作。
所有這些模組都可在任何形式的字串上運作:二進制、整數清單或混合的表示。只要您堅持使用這些模組來處理字串,您就會處於有利地位。
您必須記住的一件棘手的事情是,一個字串的編碼是隱含的。您必須知道字串進入系統時是什麼:一個 HTTP 請求通常在標頭中指定它,XML 也是如此。例如,JSON 和 YAML 要求使用 UTF-8。處理 SQL 資料庫時,每個表格都可以指定自己的編碼,但是連接到資料庫本省時也一樣!如果其中任何一個不同意,您就會損壞資料。
因此,您將需要儘早瞭解和識別您的編碼,並對其進行良好的追蹤。這不僅是您的語言中存在哪種資料類型問題,也是您如何設計整個系統以及處理在網路上交換資料的問題。
我們可以覆蓋的另一個關於字串的事情:如何有效地轉換它們。
IoData
您應該使用哪種類型的字串?有很多選擇,但選擇一個並不容易。
快速的準則為
- 代表您的大多數用法的 UTF-8 二進制檔案
- 如果您使用 UTF-16 和 UTF-32 的話,則採用 UTF-16 和 UTF-32 二進制檔案
- 實際上很少使用清單作為字串,但如果您想要在代碼點級別運作,它們會非常有效
- 對所有其他內容,特別是建立字串,使用 IoData。
二進制資料類型的其中一個優點是能夠有效地創建子切片。因此,例如,我可以來一個像這樣的內容的二進制 blob:<<"hello there, Erlang!">>,如果我比對像 <<Txt:11/binary, _/binary>> 這樣的子切片,那麼 Txt 現在參照的是 <<"hello there">>,位於與原始位置相同的記憶體位置,但無法以程式化方式取得父項關聯。這是對一個原始內容的子集的受限引用。對於清單來說就不會這樣,因為它們是遞迴定義的。
最重要的是,大於 64 位元的二進制檔案可以在程序堆疊之間共享,因此您可以以低廉的成本在虛擬機中移動文字內容,而不必像使用其他資料結構那樣支付相同的複製成本。
警告
二元共用通常是強化程式效能的絕佳方式。然而,有些病態的用法模式會導致二元共用記憶體外洩。如果你想了解更多,請查看 Erlang In Anger 關於記憶體外洩的章節,特別是 7.2 節
真正酷的事來自 IoData 表現方式,將清單方法與二元數位結合。這就是你如何取得不可變字串的極度便宜組成
Greetings = <<"Good Morning">>,
Name = "James",
[Greetings, ", ", Name, $!]
最終資料結構看起來像 [<<"Good Morning">>, ", ", "James", 33],這是一個混合清單,包含二元分區段、文字碼點、字串或是其他 IoData 結構。但 VM 機制全部支援處理它,就像平面二元字串一樣:IO 系統(網路與磁碟存取)以及先前章節中命名之模組,都無縫處理這個字串,以完全支援 Unicode 的方式,當作 Good Morning, James!
所以儘管你無法改變字串,你可以附加和比對一大堆字串,使用固定時間,無論它們最初是什麼型別。如果你撰寫有執行字串處理的程式庫,這有有趣的含意。例如,如果我想將 & 的所有案例換成 &,而我以 <<"https://example.org/?abc=def&ghi=jkl"/utf8>> 開始,我可能反而傳回以下連結清單
% a list
[%% a slice of the original unmutated URL
<<"https://example.org/?abc=def"/utf8>>,
%% a literal list with the replacement content
"&amp",
%% the remaining sub-slice
<<"ghi=jkl"/utf8>>
]
那時你擁有的就是一個實際上是 3 個元素的連結清單的字串:原始字串的一個切片、換掉的子集、原始字串的其餘部分。如果你在佔用 150MB RAM 的文件上進行換置,而且你擁有稀疏替換,你可以建立整個項目並幾乎沒有開銷地編輯它。這很讚欸。
所以 IoData 字串還有哪些酷的地方?嗯,Unicode 表現方式是其中一件有趣的事。如先前所述,重音符碼組是 Unicode 字串的關鍵層面,當你想針對這些字串進行操作時,如同人類所為(而不是只有工程師會關注的二元順序)。大多數使用平面位元組陣列來表徵字串的程式語言沒有很好的方法來反覆運算字串,然而 Erlang 的 string 模組讓你呼叫 string:to_graphemes(String) 來處理它們
erl +pc latin1 # disable unicode interpretation
1> [Grapheme | Rest] = string:next_grapheme(<<"ß↑õ"/utf8>>),
[223 | <<226,134,145,111,204,131>>]
2> string:to_graphemes("ß↑õ"),
[223,8593,[111,771]]
3> string:to_graphemes(<<"ß↑õ"/utf8>>),
[223,8593,[111,771]]
這讓你得以取得任何 Unicode 字串,並將其轉換成一個使用如 lists:map/2、清單解析或樣式比對的呼叫來反覆運算的清單。這只能透過 IoData 進行,而且這甚至可能會比你用預設 UTF-8 二元字串得到的格式更好。
請注意樣式比對在這裡仍然有風險。理想上你會想要先進行一輪標準化,這樣一來可以用多種方式編碼的字元會被迫變成統一的表現方式。
這應當有助於消除對 Erlang 字串的誤解。
時間處理
時間是非常容易過的事情,但要描述時間卻出奇困難。哲學家和科學家花了數世紀辯論才能達成一般共識,而我們軟體業者則決定採用從 1970 年 1 月 1 日開始計算秒數的方式就差不多了。但這比想像中還要複雜。我們不會深入探討日曆規則和轉換、時區、閏秒等觀念的細節,那樣的話題太廣泛了。不過,我們將探討時鐘和單調時間之間的一些重要區別,以及 Erlang 虛擬機器如何幫助我們處理這些差異。
時間背景資訊
如果你要非常簡約主義,時間測量有幾個特定應用案例,它們通常相當明確
- 瞭解兩個給定事件之間的持續時間,或「某事需要多少時間?」,需要以微秒、小時或年等單位取得單一值
- 在時間軸上定位事件,讓我們可以精確指出它並瞭解它何時發生,或「某事發生在哪裡?」,通常基於日期時間。
基本上,這兩者都與時間有關,但衡量方式並不相同。
對於 Erlang 來說,簡短的答案是,你應使用 erlang:monotonic_time/0-1 計算持續時間,並使用 erlang:system_time/0-1 計算系統時間(例如 UNIX 時間戳記)。如果你想知道原因,那麼你會想要閱讀本章節的其餘部分。
日期時間通常基於日曆日期(大部分讀者可能使用格里曆),加上給定的時、分和秒值,以及時區,並可選擇使用毫秒或微秒的高精度值。這個值需要讓人類可以理解,並且完全根植於一種社會系統,人們同意它對一段特定時間具有某種意義:我們都知道 1000 年指的是時間的特定部分,即使我們目前的格里曆是在 1582 年才引進的,而且在該系統下技術上在此之前的所有日期都不曾發生過 — 它們可能存在於儒略曆或瑪雅曆中,但不存在於格里曆中。整個概念最終會與地球軌道或平均太陽日等天文現象扯上關係。
另一方面,時間間隔,特別是對於電腦來說,是基於我們計數的一些週期性事件。漏刻或沙漏會以既定的速率滴水或沙子,當它空了,就表示經過了一段特定時間。現代電腦使用各種機制,如時脈信號、晶體振盪器,或者如果你很講究,原子鐘。通過將這些可計數的週期性事件與太陽日等概念同步,我們可以調整測量週期以獲得更廣泛的參考點,並將我們的兩個時間計量系統聯繫起來:持續時間和時間定位得以調和。
我們人類習慣將這兩個概念視為同一個「時間」值的兩個切面,但是對於電腦來說,它們同時做好這兩個概念並不容易。如果我們將這兩個概念保持區分,那將會非常有幫助:持續時間不等於時間中的絕對點,並且應該以不同的方式處理。
給個例子,很多程式設計師都了解Unix時間戳記(自 1970 年 1 月 1 日起的秒數持續時間)和UTC作為一個標準。然而,很少有開發人員知道這兩個概念實際上很難轉換,因為 UTC 處理閏秒,但是 Unix 時間戳記不處理,這可能會導致各種奇怪、有趣的問題。在程式中交替使用它們會引入微妙的錯誤。
一個特別的挑戰是電腦時鐘在長時間內不能特別精確,這個概念稱為時鐘飄移。這其中一個結果是,儘管我們可以在短時間內(幾分鐘或幾小時)獲得非常好的解析度,但是在幾週,幾個月或幾年後,時鐘飄移很厲害。電腦時鐘的頻率時不時地變化,但總體上不會有太大變化。你所進行的所有短時間計算都很好,但它們不足以追蹤大多數更長時間跨度。因此,必須透過網路使用NTP等協定,以將電腦時鐘與網路上更精確(且更昂貴)的時鐘重新同步。
這表示我們預期電腦上的時間可能會亂跳。特別是如果操作者只是玩時區或系統時間等東西的話。
在 Erlang 中處理時間
電腦處理時間的方式是基於前面提到的時鐘,其僅透過計算微秒或毫秒(視硬體和作業系統而定)來遞增。為將時間化為對人類來說有意義的單位,需要利用某些 基準點(任意起點)轉換成某些時間標準(UTC)。由於電腦時鐘會隨著時間而飄移和偏移,因此會保留一個 偏移 值,用於修正不斷增加的當地時鐘,讓它對人們來說有意義。這通常都是隱藏的,除非您知道在哪裡查看,否則您不會知道它的存在。
Erlang 的執行時間系統使用相同類型的機制,但會使它們明確化。它會公開兩個時鐘
- 一個 單調 時鐘,表示時鐘只是一個持續傳回遞增值(或與之前相同的值,如果您在相同的微秒呼叫它)的計數器。它可以具有很高的精確度,且對於計算時間間隔很有用。
- 一個 系統 時鐘,露出使用者通常會關心的人類時間。這通常會透過使用 Unix POSIX 時間(自 1970 年 1 月 1 日起的秒數)來完成,它被世界各地的電腦廣泛使用,並且還有許多轉換函式庫可供所有其他類型的時間格式使用。它提供了一種人類時間的最小公分母。
總的來說,您的系統上的所有時鐘最終可能會類似於 圖 1
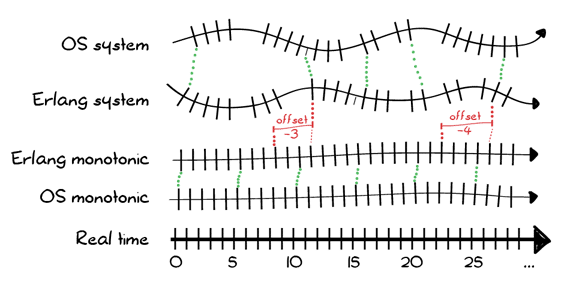
有一些實際感測時間(如果我們忽略 相對論效應,我們會假設它相當恆定),電腦時鐘多多少少能與其匹配。電壓、溫度、濕度和硬體品質都可能會影響其可靠性。Erlang VM 提供了自己的單調時鐘,其會與硬體時鐘(如果有的話)同步,並允許一些額外的控制,我們稍後會說明。
系統時間本身則永遠會計算為其底層單調時鐘的既定偏移。目標是取得硬體時鐘的任意時鐘刻度數量,並將它們轉換為自 1970 年起的秒數,然後可以將其轉換成其他格式。
如果偏移量是恆定的 0,則 VM 的單調時間和系統時間將相同。如果偏移量被正向或負向修改,則 Erlang 系統時間可能會進行調整,以匹配作業系統時間,而 Erlang 單調時間則保持獨立。實際上,單調時鐘可能是某個很大的負數,而系統時鐘則通過偏移量進行修改,以表示正面的 POSIX 時間戳記。
這表示在 Erlang 中,您會想要對特定用例使用以下函式
erlang:monotonic_time/0-1用於埃蘭單調時間。它可能會傳回超低負數,但它們永遠不會變得更負。你可以使用類似T0=erlang:monotonic_time(millisecond), do_something(), T1=erlang:monotonic_time(millisecond)的程式碼,並透過運算T1 - T0取得操作的總持續時間。請注意,時間單位應在比較中相同(請參閱注意事項)。erlang:system_time/0-1用於埃蘭系統時間(在應用偏移量後),當你需要一個 UNIX 時間戳時erlang:time_offset/0-1用於找出埃蘭單調時鐘與埃蘭系統時鐘之間的差異calendar:local_time/0用於將系統時間轉換為轉換為根據作業系統目前時鐘(意指在使用者的目前時區和夏令時間中)的{{Year, Month, Day}, {Hour, Minute, Second}}格式calendar:universal_time/0用於將系統時間轉換為 UTC 中的目前時間,其格式為{{Year, Month, Day}, {Hour, Minute, Second}}。
提示
erlang 模組中處理時間的函式幾乎都會帶有一個 Unit 參數,其可以為 second、millisecond、microsecond、nanosecond 或 native 之一。預設情況下,傳回的時間戳類型為 native 格式。單位是在執行階段決定的,而 erlang:convert_time_unit(Time, FromUnit, ToUnit) 可以用來轉換時間單位。例如,erlang:convert_time_unit(1, seconds, native) 傳回 1000000000。
calendar 模組還包含更多公用函式,例如 日期驗證、轉換 到 和 從 RFC3339 datetime 字串(2018-02-01T16:17:58+01:00)、時間差異,以及轉換為天數、週數或偵測閏年。
武裝庫中的最後一個工具是一個新類型的監控程式,可用於偵測時間偏移量跳動。它可以被稱為 erlang:monitor(time_offset, clock_service)。它傳回一個參考,當時間漂移時,接收到的訊息將會是 {'CHANGE', MonitorRef, time_offset, clock_service, NewTimeOffset}。
時間扭曲
如果你在正確的環境中使用之前的函式,你幾乎不會有處理時間的問題。你現在唯一需要注意的是如何處理奇怪的情況,例如主機電腦進入睡眠狀態並以全新的時鐘喚醒、系統管理員玩弄時間、NTP 強制時鐘快轉或倒轉等。不處理它們可能會使你的系統產生非常奇怪的行為。
幸好,Erlang VM 允許您從預設策略中挑選,只要您在正確的時間點使用正確的函數(區間和基準採用單調時鐘,系統時間用於精確定位時間事件),您就可以選擇任何您認為較為適宜的選項。挑選適合適當用例的正確函數,可確保您的程式碼避免時間扭曲。
這些選項可以通過向 erl 可執行檔傳遞 +C(扭曲模式)和 +c(時間修正)切換來傳遞。扭曲模式(+C)定義了如何處理單調時間和系統時間之間的偏移,時間修正(+c)定義了在系統時鐘變更時 VM 將如何調整公開的單調時鐘。
+C multi_time_warp +c true:時間偏移可以在任何時間變更,而無需任何限制,以提供良好系統時間,而且 Erlang 單調時鐘頻率可以由 VM 調整,以便盡可能準確。這是您希望在任何現代平台上指定的,而且往往具有較好的效能、擴充性,以及表現。+C no_time_warp +c true:時間偏移是在 VM 啟動時選擇的,然後從不修改。相反,單調時鐘會加快或減慢以慢慢修正時間漂移。基於向後相容性原因,這是預設模式,但是您可能想選擇其他更符合適當時間用法的模式。+C multi_time_warp +c false:時間偏移可以在任何時間變更,但是 Erlang 單調時鐘頻率可能不可靠。如果 OS 系統時間躍遷前進,單調時鐘也會躍遷前進。如果 OS 系統時間躍遷後退,Erlang 單調時鐘可能會暫停一會兒。+C no_time_warp +c false:時間偏移是在 VM 啟動時選擇的,然後從不修改。單調時鐘允許暫停或以大幅躍遷前進。您通常不想要這個模式。+C single_time_warp +c true:這是一種特殊的混合模式,用於在 Embedded 硬體上,當您知道 Erlang 在 OS 時鐘同步化之前就已開機(例如,您在 NTP 同步發生之前開機您的軟體)。當 VM 開機時,Erlang 單調時鐘要保持盡可能穩定,但是不會進行任何系統時間調整。一旦 OS 層級完成時間同步,使用者就會呼叫erlang:system_flag(time_offset, finalize),Erlang 系統時間就會扭曲一次以符合 OS 系統時間,然後時鐘會變成等同於no_time_warp模式下的時鐘。+C single_time_warp +c false:這是一種特殊混合模式,可於嵌入式硬體上使用,當您知道在 OS 時鐘同步之前,Erlang 已開機(例如,在 NTP 同步進行之前開機軟體)。不會嘗試將 Erlang 系統時間與 OS 系統時間同步,而 OS 系統時間的任何變更都可能對 Erlang 單調時鐘產生影響。一旦在 OS 層級完成時間同步,使用者呼叫erlang:system_flag(time_offset, finalize),Erlang 系統時間會一次變形以符合 OS 系統時間,然後這些時鐘會等同於no_time_warp下的時鐘
您通常會希望永遠使用 +c true 作為選項(這是預設值),並強制使用 +C multi_time_warp(不是預設值)。如果您想要模擬時脈頻率已調整的舊 Erlang 系統,請選擇 +C no_time_warp,如果您在嵌入式系統中工作,而第一次時鐘同步會在時間上大幅跳動,而且之後您預期它會更穩定且您不想要 +C multi_time_warp(您應該要想要它!),然後尋找 single_time_warp。
簡而言之,如果可以,請選擇 +C multi_time_warp +c true。這是準確時間控管的最佳選項。
SSL 組態
TLS 的背景資訊
即將推出…
在 Erlang 中控管 TLS
即將推出…